横跨十几个分布式服务的慢请求要如何排查?
核心目标是:定位瓶颈在哪里(是哪个服务慢了?是网络延迟?还是数据库慢了?),而不是仅仅知道最终耗时很久。
基础工具:分布式追踪系统(The Must-Have)
没有分布式追踪系统,排查这类问题几乎是不可能的。你需要一个工具来聚合和可视化请求在所有服务间的流转。
常见工具:Zipkin、Jaeger、skyWalking (国产生态友好)。
追踪系统的工作原理
- Trace ID(全局唯一请求 ID):客户端发起请求时生成,并贯穿所有服务调用。
- Span ID (服务调用段 ID):每个服务收到请求后,都会生成一个新的 Span ID 来标识自己在这次请求中的处理过程。
- 上下文传递 (Context Propagation):当服务 A调用服务B时,服务A 必须将 Trace ID 和 Span ID 通过 HITP Header 或 RPC 协议头传递给服务 B
- 数据上报:每个服务处理完自己的逻辑后,将本次Span 的开始时间、结束时间、耗时、父 Span ID 等信息异步上报给追踪系统。
排查步骤
- 根据 Trace ID 检索:通过用户的请求时间或日志,获取这次慢请求的 Trace ID。
- 查看火焰图/拓扑图:在追踪系统的 UI 上,査看该 Trace ID 对应的完整调用链的瀑布图(火焰图)
- 定位最耗时 Span:迅速找出图中颜色最深、宽度最长的 Span。这个 Span 就是主要的时间黑洞。
深入分析慢 Span 的内部瓶颈
一旦确定了是哪个服务的 Span 耗时最长,就需要深入分析该服务内部的执行细节。
- 数据库(最常见瓶颈)
- 追踪系统集成:优秀的追踪系统(如 SkyWalking)能够自动将 SQL 语句作为子 Span 记录下来。
- 查看指标:查看慢 Span 下是否有耗时较长的 DB Span。
- 问题所在:可能是慢 SQL、缺少索引、锁等待或连接池耗尽。
- 确认方法:获取慢 SQL语句,在数据库中执行 EXPLAIN(MySQL)或查看 DB 监控
- 外部 API 调用(I/O 阻塞)
- 追踪系统集成:外部 API 调用(如调用第三方接口、Redis 读写)也应该作为子 Span 记录。
- 查看指标:如果子 Span 是一个同步阻塞的外部调用。
- 问题所在:网络延迟高、第三方服务响应慢或大量并发调用导致线程阻塞。
- 确认方法:检查网络延迟,并查看调用方服务线程池的使用情况。
- 本地计算与 GC
如果慢 Span 下没有明显的子 Span(即时间主要花费在服务本身的业务逻辑上)
- 问题所在:复杂的本地计算、CPU 密集型任务、频繁的锁竞争或频繁的垃圾回收(GC)。
- 确认方法:
- JMX/Prometheus 监控:查看该服务实例在请求期间的 CPU 使用率和 GC 暂停时间.
- 线程 Dump:在请求慢时,对服务进程进行线程 Dump,查看大量线程是否阻塞在 WAITING或 BLOCKED 状态(锁竞争)
- 堆 Dump:检査是否有瞬时的大对象分配导致 Full GC 或频繁 Young GC。
架构和机制分析(宏观瓶颈)
如果瓶颈不是某一个服务,而是请求的整体流转效率低。

小结流程
- 确认 Trace lD.
- 追踪系统可视化,定位最长的 Span(瓶颈服务)
- 慢 Span 细分:查看子 Span,确定瓶颈是 DB、外部 API 还是 本地 CPU/GC
- 对症下药:如果是 DB,优化 SQL/索引;如果是外部调用,引入熔断/降级;如果是本地,分析线程和 GC
- 长期优化:改进服务间的同步调用为异步消息,缩短关键路径。
微服务中远程调用的超时时间应该设置为多少合适?
一般远程调用的默认超时时间为 2-5s。但在实际工作中,还是要看具体的业务场景,因为不同的业务场景对超时时间的要求不同。
- 一些查询、验证等较为简单的操作,超时时间可以适当缩短。
- 一些需要长时间处理的业务,比如大数据处理、复杂的查询,可能需要配置较长的超时时间,避免超时过早导致的失败。
除此之外,超时时间应该基于服务的响应能力进行设置,也就是考虑服务端(服务提供者)的处理时间,如果服务端有历史响应时间数据或监控信息,可以参考这些数据进行合理设置,例如参考 TP99 的耗时来设置超时时间, 整体的配置根据当前的上下游服务情况敲定一个合理的超时时间。
一般来说,建议服务端(服务提供者)提供配置超时时间和重试次数等参数,因为作为服务提供方,它比消费方更清楚当前服务、方法的性能。而消费者直接采纳生产者提供的配置即可,
- 远程调用超时时间
在微服务场景,远程调用超时时间,一般指的是生产者(provider)和消费者(consumer)配置的方法调用超时时间。
超时时间无法设置过短。如果时间过短,正常业务流程还未走完,消费者检测到接口超时,直接中断调用,影响正常业务的执行。超时时间无法设置过长。如果时间过长,此时请求量较大,那么就会出现大量长期无响应的请求占用线程池等情况,导致资源被占用无法释放,严重会导致服务崩溃因此超时时间的设置需要比正常业务耗时长,但是又不能长太多,建议根据压测情况。参考TP99 的耗时来设置超时时间。
TP99 指的是满足 99%次数的网络请求所需要的最低耗时。比如调用一个方法,1小时内调用了 10w次,监控显示 TP99 是 300mns,这个意思就是:这个请求强度下,百分之99% 的调用,都可以在 300ms 内返回结果,此时超时时间可以设置为 1s,给一定的冗余又不会太多,此时设置10s就是过长的配置。
- RPC 框架的多粒度超时时间
例如 dubbo 支持多粒度配置 rpc 调用的超时时间:优先级从高到低依次为 方法级别配置>服务级别配置 >全局配置 >默认值。
- 配置全局默认超时时间为5s (不配置的情况下,所有服务的默认超时时间是 1s)
dubbo:
provider:
timeout: 5000- 在消费端,指定 DemoService 服务调用的超时时间为 5s
@DubboReference(timeout=5000)
private DemoService demoService;- 在提供端,指定 DemoService 服务调用的超时时间为 5s(可作为所有消费端的默认值,如果消费端有指定则优先级更高)
@DubboService(timeout=5000)
public class DemoServiceImpl implements DemoService{}- 在消费端,指定 DemoService sayHello 方法调用的超时时间为 5s
@DubboReference(methods = {@Method(name = "sayHello", timeout = 5000)})
private DemoService demoService;- 在提供端,指定 DemoService sayHello 方法调用的超时时间为 5s(可作为所有消费端的默认值,如果消费端有指定则优先级更高)
@DubboService(methods = {@Method(name = "sayHello", timeout = 5000)})
public class DemoServiceImpl implements DemoService{}现在手头上有一个单体项目,系统的整体 QPS 到了1万了,要微服务化拆分吗?
不一定,因为是否要微服务化拆分,主要关注系统瓶颈、业务复杂度、团队的情况,而非单纯看 QPS
先明确系统是否有瓶颈
如果 QPS到1万后,单体应用仍能稳定运行(CPU/内存/GC正常),只是需要加机器扩容,不建议拆分。单体架构在垂直扩展(加内存、CPU)上更简单高效!
但是,如果出现以下情况,说明单体架构已到瓶颈,建议拆分:
- 部分模块资源消耗不均(如某接口占80%流量,拖慢整个应用)
- 开发效率下降(代码库庞大,修改一处影响全链路,测试和部署都很耗时)
- 故障隔离差(一个模块崩溃导致整个服务不可用)
- 技术栈无法升级(如部分模块想用Go优化,但单体架构绑定语言)
判断业务复杂度
实际上如果出现开发效率下降已经能反应出业务复杂度不低。此时可以进行业务边界分析,看边界是否清晰,即系统是否已有明显的功能域划分,可拆分成独立服务。因为部分模块是可以预想到后续的改动会比较大,且流量也会比较大,此时根据公司的增速预测后续的用户新增曲线,预先划分出部分服务,减少后续的改动成本
团队的情况
服务是否拆分,与人有关,极端一点,如果目前团队只有1个人,然后拆了十几个微服务,此时带来的坏处,可能远多于好处。你想想看,一旦本地调试,你需要起 10 个服务,那种感觉,谁来谁知道。因此,要根据团队的人员数来评估是否需要拆分微服务和拆分微服务的个数。
一个团队内部沟通成本和人员数有关,随着人员数(n)的增加沟通成本呈指数级增长(n-1)/2,一般会划分成每个小团队来负责一部分功能的开发和维护,大致为2~4人(具体情况具体分析)。
实际上,如果单体项目真的遇到瓶颈,我们可以先优化单体,再考虑拆分。
最简单的优化例如:
- 缓存(如Redis):减少 DB 压力,QPS 可能提升数倍
- 异步化(如MQ):削峰填谷,提升吞吐量
- 分库分表:解决数据库瓶颈
- 代码优化(如减少锁、优化算法)
如果优化后仍无法满足需求,再考虑微服务拆分。
记住一句话:是否微服务化,不是 QPS 数字决定的,而是业务发展和架构瓶颈倒逼的。
那到底什么情况该拆
简单举两个例子:
- 不拆的案例:某内容平台QPS 2万,但 90%是读请求,通过加Redis集群、数据库分片、前端页面静态化,3人团队就能维护,业务逻辑简单。这时候拆了就是冤大头
- 要拆的案例:某金融系统 OPS 5000,但支付、风控、对账模块频繁改动目互相阻塞,拆成做服务后,风控规则独立灰度上线,支付服务按流量自动扩容,大大提升系统的鲁棒性和开发效率,这就是要拆的情况
所以当业务模块差异大(例如电商的订单和风控逻辑)、团队规模扩张(10人团队振成3个小组独立开发)、需求迭代频繁(比如A模块每天上线,B模块每月一次),这种场景适合拆。
不过也需要考虑拆之后的代价,例如需要分布式事务、调用链追踪、服务治理(熔断、限流),这些都会增加开发运维成本,小团队可能扛不住。
会员表中有500万条会员数据,有什么方式可以对即将过期的会员提前7天进行提醒?
概括来说就是:定时任务+索引优化+异步通知,
每天业务低峰期跑一次定时任务,筛选出 “过期时间 = 当前时间+7天”的会员数据,需要在会员表的“过期时间”(如expire date)字段上建立索引,避免全表扫描。
这里还需要分页查询即将过期会员的数据,例如300条每批,防止内存占用过大。得到待提醒的会员ID 扔到消息队列中,有消费者异步发送短信或邮件等方式处理。(在意提醒时间可以通过延迟消息)
定时任务
如果是简单的单体架构,可以使用 Spring @scheduled 。
若系统是分布式架构,可以用 XXL-JOB 等框架更可靠,能避免单点故障,还支持任务分片,如按会员ID范围分片查询,提升处理速度
索引优化
对“过期时间”字段建立索引:如MySQL的 CREATE INDEX idx_expire_time ON member(expire_time)
查询筛选语句:SELECT * FROM member WHERE expire_time= CURDATE()+ INTERVAL 7 DAY 就能用上索引。
分页查询:逐步处理,具体分页大小可自行调整。
其它优化
如果后续表继续膨胀,可以进行冷热数据分离,如将历史过期会员归档到历史表,减少主表体积。
如果害怕查询影响主库性能,可以利用读写分离,从库执行查询任务,避免影响主库写入。
其他方案
Redis 过期监听
- 会员表中插入数据时,同步在 Redis 存储这个会员 ID,同时设置过期时间(提前7天)
- 然后利用 redis 的过期提醒功能
- 监听服务捕获过期事件,然后处理通知
在Redis 的配置文件(redis.coanf) 中,需要配置 notify-keyspace evens 选项来控制哪些事件会被发布。要启用键过期事件通知,可设置为 notify-keyspace evens Ex,其中E代表事件通知,x代表键过期事件。修改配置后,需重启 Redis 服务器使配置生效。
用户登录时检测
每天用户登录系统,自动触发检测,如果发现会员过期时间小于配置的值,则触发通知。
这样的设计压力最小,但是如果用户一直不登录就没办法提醒到。
即时通讯项目中怎么实现历史消息的下拉分页加载?
一般在即时通讯项目(比如聊天室)中,我们会采用下拉分页的方式让用户加载历史消息记录
区别于标准分页每次只展示当前页面的数据,下拉分页加载是 增量加载 的模式,每次下拉时会请求加载一小部分新数据,并放到已加载的数据列表中,从而形成无限滚动的效果,确保用户体验流畅。
比如用户有 10 条消息记录,以5条为单位进行分页,刚进入房间时只会加载最新的5 条消息:

下拉后,会加载历史的第 6-10 条消息
理解了业务场景后,再看下实现方案,为什么不建议使用传统分页实现下拉加载?
传统分页的问题
在传统分页中,数据通常是 基于页码或偏移量 进行加载的。如果数据在分页过程发生了变化,比如插入新数据、删除老数据,用户看到的分页数据可能会出现不一致,导致用户错过或重复某些数据。
举个例子,对于即时通讯项目,用户可能会持续收到新的消息。如果按照传统分页基于偏移量加载,第一页已经加载了第1-5行的数据,本来要查询的第二页数据是第6-10 行(0应的SQL语句为 limit 5m5),数据库记录如下:

结果在查询第二页前,突然用户又收到了5条新消息,数据库记录就变成了下面这样。原本的第一页,变成了当前的第二页!

这样就导致查询出的第二页数据,正好是之前已经查询出的第一页的数据,造成了消息重复加载。所以不建议采用这种方法。
推荐方案-游标分页
为了解决这种问题,可以使用游标分页。使用一个游标来跟踪分页位置,而不是基于页码,每次请求从上一次请求的游标开始加载数据。一般我们会选择数据记录的唯一标只符(主键)、时间戳或者具有排序能力的字段作为游标、比如时通讯系统中的每个消息,通常都有一个唯一自增的ID,就可以作为游标,每次查询完当前页面的数据后,可以将最后一条消息记录的 id 作为游标值传递给前端(客户端)。

当要加载下一页时,前端携带游标值发起查询,后端操作数据库从id 小于当前游标值的数据开始查询,这样查询结果就不会受到新增数据的影响。

对应的SQL语句为:
SELECT * FROM messages
WHERE id < :cursorId
ORDER BY id DESC
LIMIT 5;使用游标的优点
使用游标分页除了能解决数据不一致(数据重复)的问题,还能起到性能优化的作用。
游标分页通常比基于偏移量(offset)的分页更高效,因为传统的偏移分页需要那过一定数量的记录,随着偏移量的增加,查询性能会下降,而游标分页只需要查询自上一个游标之后的记录,可以利用数据库索引进行快速定位,直接跳到该值的位置,从而减少了数据库的扫描和处理负担,提高了查询速度。
游标分页的应用场景
游标分页的应用场景很多,特别适用于增量数据加载、大数据量的高性能查询和处理,除了 系统获取历史消息记录之外,常见场景还有社交媒体信息流、内容推荐系统、数据迁移备份等等,
如何选择游标字段
一般游标字段要具备以下特性:
- 唯一性:要确保在分页过程中能够准确地定位记录。
- 排序稳定性:游标字段的排序结果要相对稳定,避免分页过程中数据的丢失或重复。
- 性能:游标字段一般要设置为索引,以确保分页操作的高效。
- 避免频繁变化:避免使用频繁变化(实时更新)的字段,减少分页时记录丢失或重复的情况。
对于即时通讯项目的消息记录,除了ID之外、还可以选择时间戳作为游标,因为 IM 系统中,消息通常是按照时间顺字排列和查询的,时间戳想供了一种自然的排序方式,能够避免由于数据插入或删除造成的数据不一致问题。
但是也要注意,如果时间戳的精度不够(如秒级),高并发情况下可能会出现时间戳重复,从而导致分页结果中的数据丢失或重复。
所以一种更规范的方案是,使用 时间戳加 ID 字段作为复合游标,在时间戳相同的情况下,通过 ID 确保唯一性和稳定性。
示例 SQL语句如下:
SELECT * FROM messages
WHERE (timestamp < :cursorTimestamp OR (timestamp = :cursorTimestamp AND id < :cursorId))
ORDER BY timestamp DESC, id DESC
LIMIT 10;你项目用的 JWT,那如何保证安全性?别人拿到你这个Token 不就可以直接登录你的账号了吗?怎么办?
基本上 JWT 一旦被窃取就等于家里钥匙被人偷了,所以可以直接登录我们的账号。
不过还是能通过一些手段尽可能地避免这种情况的发生和及时处理。
首先我们网站要用 HTTPS 传输,避免 JWT 在网络中被中间人截获。
还要防止 XSS(跨站脚本攻击)和 CSRF(跨站请求伪造)。
- XSS:如果你把 Token 存在 localStorage,被注入 JS 拿到就完了。可以考虑存 HttpOnly Cookie 来防止 JS 访问。
- CSRF:如果用 Cookie 传Token,那就要加上 CSRF Token 验证,防止别的网站伪造请求。
生成 JWT 时,可以把用户的IP、浏览器信息(UA)也编码进 JWT Payload。使用时对比环境是否一致
Token 要设置短有效期限,即使 Token 泄露,攻击者也无法长期冒用。像一些关键操作还需要二次确认,比如修改密码、提现之类的加上手机号验证码二次验证。
JWT 是无状态的,但遇到 Token 泄露时,需要主动吊销。我们可以在 Redis 维护一个黑名单:
- 当用户注销、Token 泄露时,将 Token 加入黑名单。
- 每次接口调用时,先检查 Token 是否在黑名单中。若在,直接拒绝
如果要实现一个抢红包的功能,红包金额是如何计算的?
抢红包的金额计算核心是公平性和总额控制,核心逻辑分两种场景:
- 普通红包(固定金额):这个比较简单,每个红包金额完全相同。比如总金额 100元,发10个红包,每个红包固定10元。逻辑很简单,直接用总金额除以红包数量即可。
- 随机红包:每个红包金额随机,但需满足两个条件:
- 所有红包金额之和等于总金额
- 单个红包金额不能为0,且需保证“先抢和后抢的人有公平的随机概率”(比如不能让前面的人抢走大部分,后面的人只能抢几分钱)。
行业主流用实时计算结合二倍均值法实现随加红包:每次分配时,当前可分配的金额为剩余金额,剩余数量为n个红包,则当前红包的金额上限是(剩余金额/剩余数量) * 2。,下限是1分。这样既保证了随机,又能让后续红包有合理金额。
除了实时计算外,还有预先生成的方案:在发红包时用线段分割法提前分配好所有金额存入队列,抢红包时直接按顺序取即可
二倍均值法的具体例子
假设总金额10元(我们转成 1000 分),发5个红包:
第一个红包:剩余1000分,剩余5个,上限是(1000/5) * 2 = 400分,随机范围1~400分。假设随机到300分,剩余700分,剩4个红包
第二个红包:剩余700分,剩余4个,上限(700/4) * 2=350分,随机范围1~350分。假设随机到200分,剩余500分,剩3个红包.。
以此类推,直到最后一个红包直接拿剩余所有金额(避免前n-1个红包分完后最后一个为0)。
线段分割法(预生成)
把总金额想象成一条长度为M 的线段(如10元=1000分)
然后随机切 N-1 刀生成分割点(N=人数),最后按分割点位置计算每段长度作为红包金额。
实际开发中的细节
- 最小单位 金额需用“分”(整数)而不是“元”(浮点数),避免浮点精度误差(比如0.1元用浮点数存储可能有误差)
- 并发控制:像群里面的红包实际上并发还好,微信群最多也就500人。
- 红包过期:若红包未被抢完,超时后需退回原账户,此时需记录已抢金额和剩余金额,避免重复退款。
如果面试官追问并发相关的问题,可以参考 如何设计一个秒杀功能
如果一笔订单,用户在微信和支付宝同时支付,会怎么样?
微信和支付宝都会支付成功,因为支付渠道是第三方系统,它们之间的数据是不相通的,因此无法阻止用户付款。

这样一来同一笔订单,用户就会多付了一笔钱,如何避免这个情况?
思路其实很清晰,不管是支付宝支付还是微信支付,用户支付后三方都会进行回调,这个回调处理逻辑在我们的系统中,因此我们可以在这里控制。
支付单都会有状态机,例如从支付中到支付成功,比如 update pay_info set status = "sucess” where pay_no ='123' and status = "paying'
通过数据库对单一记录的更新加锁来保证先到的回调支付状态就能修改成功,后到的回调修改状态失败(因为where 条件不匹配,影响行数为 0)。针对影响行数为 0的那次回调,我们就可以调用退款流程把用户多付的钱给退了,假设微信支付回调执行成功,支付宝回调执行失败:

不过这里还有一个很关键的点需要注意,即支付回调的幂等性处理
因为支付渠道回调我们后端服务,后端需要给对应的响应,不然支付渠道会重试回调,假设因为网络抖动或者其他因素号致支付渠道重复回调,必然会触发SOL执行失败,如果不做任问处理,肯定会触发退款流程了!那前况完了,钱有很给
用户,产生了资损。
这里的做法是需要在支付单中记录支付成功的渠道和对应的渠道支付单号,增加这部分的判断就能实现幂等,回调随便调,不会影响业务.。
例如支付单增加:
pay_channel:支付渠道(如微信、支付宝等)
transaction_id:渠道支付单号
流程如下:
- 判断支付单是否已完成支付
- 若已完成,则检查支付渠道和支付单号是否匹配。
3. 若匹配,说明重复支付,直接返回
4. 若不匹配,说是其他渠道,调用退款接口 - 若未完成,执行上述 update 逻辑,并将检查支付渠道和支付单号一并落库
- 如果 update 影响行数为0,说明已经被其他渠道支付了,可以不返回响应,待三方支付再次回调,走上述的第二步逻辑(因为不确定是不是同渠道多次清求)。
如何避免用户重复下单(多次下单未支付,占用库存)
这个其实就是幂等性的问题
在稀有商品抢购或秒杀场景中,一个用户多次下单未支付可能是恶意锁库存或损坏其他用户的权益,因此需要避免用户重复下单。
首先前端需要进行按钮控制:在用户点击“下单”按按钮后,可以通过前说控制技钮状态,比如变为“如理中”或“请稍等等”,造免用户在等待过程中多次点击波讯,导致重复下单清求发送到后说,但是的品的操作无法完全避免重复清求,因此需要与后端的憙等控制结合以确保不会因多次点击创建多个订单。
在每次下单请求中生成一个唯一的 requestId 或 token:
用户进入订单页面前,前端会先清求后端生成这次请求的唯一的requestId 或 token,然后在每次下单去请求中带上这个唯一的 requestId 或 token。这样后端可以通过检测该标识是否已存在,来决定是否创建新订单,这样,无论用户重复点击几次下单按钮,仅会创建一次订单。
以上两步能阻挡绝大部分用户正常操作下的重复下单行为,如果一些用户通过api请求,或者后退页面再次点击下单进入,还是可以重复下单,不过一般这种设计已经可以杜绝稀有商品抢购或秒杀场景的恶意锁库存了,因为后退页面让下单流程再走一遍还是比较费时的。
- 分布式锁 + 判断 +下单
4. 以用户维度,加上分布式锁,例如分布式锁的 key 中的内容可以是 xxx+userd,这样同一个用户的操作会被锁定。
5. 判断用户是否有在流程中未支付的订单。
6. 如果没有则正常进行下单流程
7. 如果有则直接返回,提醒前端您还有未支付的订单,请先支付后再继续下单!
这样就能保证用户无法重复下单(恶意占用库存锁单)
唯一索引实现幂等的约束
上述第二步在实现幂等性时说到,可以为每个订单请求设置一个requestId 或 orderToken 。具体是在订单数据库中保存该唯一标识,建立唯一索引。当新订单清求到达时,首先检查数据库中是否已有相同标识的订单记录,如果有则直接返回订单信息,避免重复创建而且有唯一索引兜底,即使因为并发导致读取判断没数据,但实际有数据的情况,也会因为唯一索引从而避免重复插入。但是唯一索引来实现幂等还是有很多局限性。
- 业务逻辑需要依赖异常(DuplicateKeyException)
try {
// 尝试创建订单
return orderRepository.save(order);
} catch (DuplicateKeyException e) {
// 捕获重复键异常,说明订单已存在,返回现有订单
log.info("订单已存在,返回现有订单信息");
return orderRepository.findByRequestId(requestId);
}《Effective Java》 提出一条建议:不要用异常去控制程序的流程。
主要因为以下几点:
- 性能开销:异常在 Java 中是重量级的操作!
异常的创建成本高:当抛出异常时,JVM会捕获当前堆栈信息,用来构建异常栈追踪,这是一项耗时的操作。 - 异常捕获过程耗时:异常抛出后需要经过堆栈的传递来找到匹配的catch块,尤其在异常频繁抛出的场景中,性能开销会更加显著。因此,用异常做流程控制会显著影响程序性能,尤其是在高并发、性感的应用中。
- 代码可读性差:异常的存在往往意味着出现了非预期的情况,如果用异常来控制正常流程,会让开发者误解代码意图,难以分辨哪些是正常流程,哪些是错误处理。
- 依赖底层类: DuplicateKeyException 是 Sping 中的类,后续如果进行框架迁移不或者升级使得不报这个异常了,那就尴尬了。(面试时候说可以这样说,但是我觉得问题不大。。)
- 数据库压力大
等于把所有的请求,即使是重复的请求都需要靠数据库来做唯一判断,把压力都给到数据库身上,在高并发情况下会产生比较大的压力。 - 业务局限
大部分的准一索引防重都需要插入操作,即 insert动作,部分update也可以用上唯一案引但是场景比较少。不过这种情况一般我们在业务上会增加一个流水表来创造一个 insert 语句来实现前置防重(话是这么说,但流水表不是主要为了创造一个 insert,本身流水还是追溯和审计等意义的)。
如何设计一个 OAuth2.0 授权服务?Token 如何管理?
OAuth2.0 授权服务主要设计四个角色,分别是:
- 用户(资源所有者)
- 第三方应用(客户端)
- 授权服务器(我们设计的)
- 资源服务器(如用户信息接口)
以授权码模式为例,微信登录为背景,主要流程是
- 用户访问第三方应用,点击“使用微信登录
- 客户端跳转到授权服务器,用户输入账号密码登录授权
- 授权服务器返回 授权码 code
- 客户端拿着 code 换取 access token、Refresh Token等
- 客户端用 token 访问资源服务器接口

关于 Token 管理的,要做到:
- 安全性:Access Token 用 JWT 或 UUID 确保唯一性,添加时间戳、签名防篡改。Refresh Token同理
- 生命周期管理:需要设置合理过期策略(如 Access Token 15分钟,Refresh Token 7天),支持主动失效(如用户登出)
- Token 传输用 HTTPS
项目上需要导入一个几百万数据 excel文件到数据库中,有哪些注意点?
对于百万数据的导入,一般需要关注三类问题:
- 内存,如果一次性在堆内加载过多的数据,可能会导致内存溢出。
- 时间,百万数据插入数据库需要一定的时间,同步调用可能会使得方法超时,
- 异常,百万数据中可能会有很多异常的情况,比如格式错误、重复数据等等。
内存是有限的,不能一次性将 excel内的所有数据都加载到内存中,需要分批加载
像 apache poi会将整个文件加载到内存中,内存占用较高,而 easyexcel则是基于 sax 解析,逐行读取数据,避免将整个文件加载到内存中,因此可以采用 easyexce框架读取文件,避免内存溢出
excel 单 sheet 存储的文件是有上限的,需要保证 100w条以内,因此如果是几百万的数据,单文件肯定是多 sheet。我们可以针对 sheet数量起对应的线程进行多线程读取,这样可以如快读取的速度,并且不要读取一条数据就调用数据库进行保存,我们可以需要批量保存,比如载 500 条数据到内存中,存在 list 内,然后调用数据库批量保存接口,一次性保存这些数据,这样会大大提升插入的速度。
最后异常的处理,一般业务上会跳过异常的数据,继续日志记录,等文件导入完毕后,再单独处理这些数据。
项目上有个导出 excel 场景发现很慢,怎么优化?
- 先定位慢在哪儿?需要定位导出 excel 慢在哪里
- 业务逻辑慢?
- 数据库查询慢?
- excel 生成慢?
- 针对性解决慢的问题
- 如果是业务逻辑处理很慢,则需要优化调整逻辑,比如将一些在循环内的多次 RPC 调用,变成一次(或更少)的批量 RPC 调用。
- 如果是数据库查询慢,则查看 SQL是都命中索引,是否有额外的排序逻辑等等。一般情况下导出的场景都会分页查询数据库,可以将普通分页使用的 Limit offset,size变成记录上一次查询的 id 为 lastld,然后下次查询的时候带上 lastld 作为查询条件。例select * from table where id >lastId +(其他过滤条件) order by id asc limit size ;因为 Limit offset,size的效率比较低,例 limnit 100000,10,则是一直扫描到10000后,跳过它们,再取接下来的10条数据,对数据库来说这需要大量的 IO 操作 (扫描这么多行)。详情可以看大分页 limit
- excel 生成慢的话一般只要避免一行一行写入即可。即批量写入数据,而不是一行一行写入。
- 多线程优化:上面优化过后,如果还想缩短导出的时间,则需要进行多线程操作。
将要导出的数据进行分片,比如以”地方“为分片依据,北京的一个sheet、上海的一个sheet 以此类推,多线程并发处理不同sheet 数据的获取和写入(或者多个 excel)文件都行,最后生成一个zp 包输出就好了)。大数据量的情况下注意使用流式导出,防止占用过多内存,POI使用 SXSSF,EasyExcel默认就是流式导出。
public class ExcelExportService {
private static final String EXPORT_DIR = "path/to/export/directory"; // 临时文件存储目录
//从数据库查询数据
public List<Data> getDataByPlace(String place) {
List<Data> dataList = new ArrayList<>();
...
return dataList;
}
// 数据导出:根据地方分片生成不同的 Sheet
public void exportDataForPlace(String place, String filePath) {
List<Data> dataList = getDataByPlaceFromDB(place);
// 使用 EasyExcel 写入数据到 Excel 文件的不同 Sheet
EasyExcel.write(filePath, Data.class)
.sheet(place) // 每个地方对应一个 Sheet
.doWrite(dataList);
}
// 执行导出任务,采用多线程并发
public void export() throws InterruptedException, ExecutionException {
// 1. 定义地方列表
List<String> places = Arrays.asList("北京", "上海", "广州", "深圳", "杭州");
// 2. 设置线程池来并发处理不同地方的导出任务,此为 demo,真实环境线程池需要提前定义,
// 不可每次执行都创建
ExecutorService executorService = Executors.newFixedThreadPool(places.size());
List<Future<?>> futures = new ArrayList<>();
// 3. 创建 Excel 文件路径
String filePath = EXPORT_DIR + "/places.xlsx";
// 4. 执行每个地方的导出任务
for (String place : places) {
Future<?> future = executorService.submit(() -> {
try {
exportDataForPlace(place, filePath); // 导出数据到对应的 Sheet
} catch (Exception e) {
e.printStackTrace();
}
});
futures.add(future);
}
// 5. 等待所有任务完成
for (Future<?> future : futures) {
future.get();
}
// 6. 关闭线程池
executorService.shutdown();
System.out.println("mianshiya Excel export has been completed.");
}
}更多详情可以看整合EasyExcel - 实现百万数据导入导出
一笔订单,在取消的那一刻用户刚好付款了,怎么办?
这种情况在正常的业务场景中是有可能出现的,因为订单都会有定时取消的逻辑,比如10 分钟或者 15分钟,而用户刚好卡在这个时间点进行付款,此时就会出现两种情况:
- 用户支付成功,支付回调的那一刻支付单刚好还没取消,而等回调结束,取消支付单的事务提交,支付单取消。此时用户扣款了,但是对应的权益或资产没了。
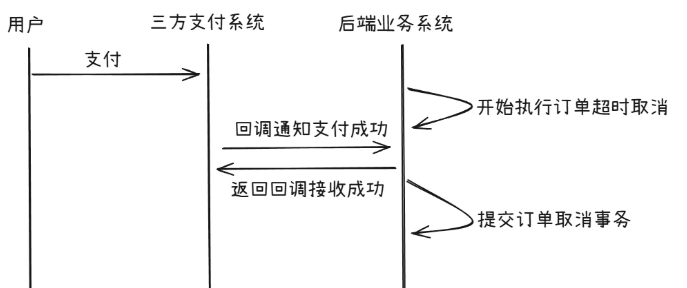
- 用户支付成功,支付回调的那一刻支付单已经被取消。但此时用户已经扣款,东西却没了
可以看到,不论是哪种情况,其实都需要做一定的处理,不然用户肯定会来投诉!
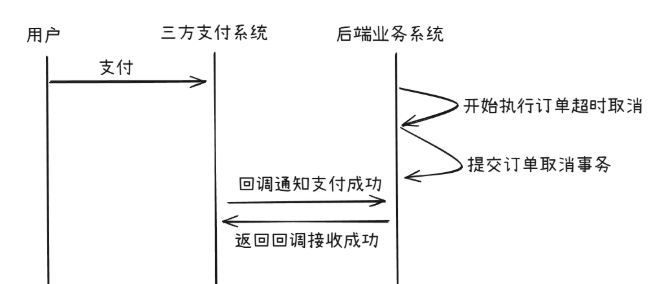
这种场景无非就是支付单支付成功和取消两种状态的“争夺”,正常情况下,订单或者支付单都会有状态机的存在,在当前场景简单来说有以下两条路径:
- 待支付->支付中->支付成功
- 待支付->支付中->已取消
针对情况1,如果是支付回调取胜,此时的状态应该已从 支付中->支付成功
针对情况2,如果是取消支付单取胜,此时的状态应该已从 支付中->已取消
所以我们在修改支付单状态的时候,基于原始状态的判断,就可以做正常的处理,来看下 SOL应该就很清晰了:
# 支付成功
update pay_info set status = 'paySuccess' where orderNo = '1' and status = 'paying';
# 取消
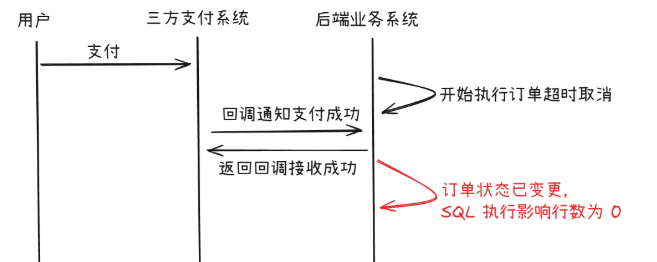
update pay_info set status = 'cancel' where orderNo = '1' and status = 'paying';重点就是我们加了 status='paying’这个条件,这就能保证情况只有一个能成功,另一个一定失败。这种其实就是乐观锁的方式
- 假设情况1成功了,此时用户已经成功付款,那么状态已经变为paySucces,取消的SQL必定执行失败,此时就让它失败,不需要做任何别的处理。
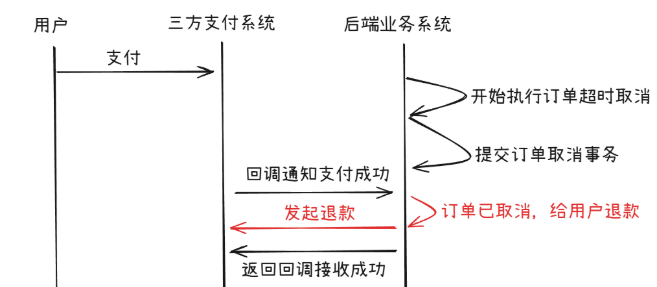
- 假设情况2成功了,此时订单已被取消,status已经变为 cancel,支付成功的SOL必定执行失败,这种情况下我们就需要做逆向处理,即给用户退款。订单被取消,用户的钱也被原路退回,这种处理也没任何问题
业务优化
针对订单超时业务,这里在业务上可以做一个小优化,你想想,用户付款前可能有点挣扎,然后在最后一刻终于下定决心进行付款,这时候却告知被退款了,用户很可能就不会再下单了。因此我们在页面上可以限时订单取消设置计时为 10分钟,但实际后端是延迟 11 分钟取消订单,这样就能避免这种情况的发生啦。
Redis 分布式锁实现
最后除了利用数据库处理,还可以使用分布式锁,对一笔订单加锁也能保证这笔订单正常的业务流转。每次进行取消订单或付款操作时,首先尝试获取订单的分布式锁,确保只有一个操作能修改订单状态。在分布式系统中,订单在取消的同时用户付款的竞态问题可以通过分布式锁来解决。以下是一个具体的、落地的方案,确保订单状态的可靠性,避免因并发导致状态冲突
订单取消流程:
- 超时触发取消订单
- 取消订单方法中先获取该订单的分布式锁。如果锁被其他操作持有(如付款),等待或抛出异常
- 若成功获取锁,检查订单状态是否已付款:
- 若订单未付款,将订单状态更新为“已取消”
- 若订单已付款,直接跳过这笔订单的处理。。
- 释放分布式锁,完成取消流程。
订单付款流程:
- 三方支付成功回调。
- 后端系统接收回调后,先获取该订单的分布式锁,如果锁被其他提作持有(如取消),等待或抛出异常(没有给三方响应成功,三方会重新发起回调)
- 若成功获取锁,检查订单状态是否为“待支付”:
- 若订单状态为“待支付”,继续执行扣款,并将订单状态更新为“已付款”。
- 若订单状态为“已取消”,则发起退款,并提示用户订单已取消,无法支付。
- 释放分布式锁,完成流程。
针对支付宝最近出现的八折优惠事故,说说如何才能避免类似事件的发生?
根据官方回应出现 bug 的原因是运营人员配置错营销模板导致的,即优惠额度和优惠类型都写错了。
失误是怎么发生的?其实是我们在支付宝某个常规营销活动后台配错了营销模板,把优惠额度、优惠金类型都写错了,
实际上,类似的人为错误是难以完全避免的,作为开发人员,我们可以从产品和技术的角度出发,思考如何尽量降低人为失误的发生几率,并通过及时的预警、拦截等机制,在出错后减少资损
从产品侧思考
很多敏感场景我们需要防呆设计”,例如用户需要输入日期这个场景,程序通过日期格式验证(如:YYYY-MM-DD),并目如果用户输入不合规范(例如输入2025-31-12,超出合理范围),则程序给出错误提示并要求重新输入,这其实就是防呆设计。
回到面试场景,针对资金、资产相关配置,产品上的设计可以考虑以下几点:
- 多重审核:营销模板系统可以设计一个"草稿-审校-发布”的流程,确保在发布之前,经过多重人员审查,避免因配置指误导致资损。(不清楚为什么支付宝这次会出现这样的错误,因为这种配置按照正常流程肯定是多重审核的)
- 多个优惠类型的冲突检测:在配置多种优惠时,系统应该检查不同优惠类里的冲突,例如,如果一个活动允许使用“满减“优惠,同时又允许使用“折扣“优惠,系统需要确认两者是否允许叠加使用,或限制其只能生择一种优惠。产品侧需强提醒(例如弹框)运营当前优惠有叠加,是否确认配置
- 合理校验优惠额度上限:在设置优惠额度时,系统应该能够检查是否超过了预设的上限、例如,对于某些活动,优惠额度不能超过商品价格的 100%(避免用户获得免费商品)。如果优惠类型为折扣,系统应确保折加比例在合理范围内,如果优惠力度过大,则需要强提醒(例如弹框),比如优惠了70% 这种。
- 合理校验优惠范国:如果优惠品类过多,例如选择了几十种品类,或者直接选择了全品类这种范围的优惠也需要强提醒,进行二次确认,甚至三次确认(选择全品类时一次确认,最终提交时候再次确认)。
从技术侧思考
- 即时监控和告警:对于优惠活动的应用情况,设计实时监控机制,任何不符合预期的异常(如优惠幅度异常、超出预算等、要第一时间告警、比如:如果在短时间内大规模用户(像以前pdd的拉新活动,变成了所有用户可享,很明显粉丝量肯定是异常的)都获得了折扣,可以通过日志分析和支付流水对比,及时发现异常。
- 环境隔离:测试环境和正式环境一定需要有严格的隔离机制,例如网络隔离、数据源隔离等等,因为有太多太多问题是因为测试教据流入正式环境导致的(因为测试往往需要改价,配置大额优惠券等)
- 自动熔断:针对一些优惠可以预设一个资金池,即最大优惠总额,当超过预设的范围则自动熔断,后续所有优惠直接失效,,防止资损进一步扩大。(实际上大部分营的活动都有一个优惠预期,最大优惠总额可以比优惠预期多一些)
- 系统默认兜底检查:例如同一用户多次掘时间内享受了优惠、优惠领度不能过商品价格的10%等等,很多时候我们写代码都需要考虑完全,这样代码和产品才会健壮,即尽可能的避兔人为的错误产生影响(把系统的使用者当成呆子。他们就是会做一些神操作,而你就是系统的最终守护者!)
SpringBoot 工程启动以后,希望将数据库中已有的固定内容提前加载到 Redis 缓存中,应该如何处理
这个问题说白了就是希望通过预加载数据,达到提升系统性能和响应速度的效果。像目前在很多场景中都有使用:
- 电商平台的商品分类信息、用户基础资料:避免高并发时数据库被重复查询,降低响应延迟。
- 系统参数配置(如地区编码、权限规则)、国际化资源:减少对配置中心或数据库的依赖,提升配置读取速度。
- 促销活动的商品库存信息、新闻头条内容:通过预加载防止缓存击穿,应对突发流量。
题目说的是提前加载的redis缓存中,像配置类信息等这种变更频率低、实时性要求低的数据,还会加载到本地缓存中(如GuavaCache,Caffeine等),进一步减轻redis的压力,提升访问速度
重点
重点其实就是利用Spring 或 SpringBoot的扩展点来完成这部分功能
初始化数据加载触发机制
- 使用 CommandLineRunner或ApplicationRunner 在应用启动时自动执行数据加载逻辑。这是最常见的实现方式。
@Component
public class CacheWarmupRunner implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) {
// 分页加载数据到缓存
PageHelper.startPage(1, 1000);
List<Product> products = productMapper.selectAll();
products.forEach(p -> redisTemplate.opsForHash().put("products", p.getId(), p));
}
}- 使用 @PostConstruct 注解
在服务类中通过 @Postconstruct 注解标记等初始化方法,在 Bean 创建后立即执行数据加载
@Service
public class CachePreloader {
@Autowired
private UserService userService;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@PostConstruct
public void init() {
List<User> users = userService.getAllFixedData(); // 从数据库获取数据
users.forEach(user ->
redisTemplate.opsForValue().set("user:" + user.getId(), user)
);
}
}结合缓存注解主动触发
使用 @Cacheable 注解:在首次调用方法时触发缓存写入,强制触发缓存写入。但需手动触发首次调用才能完成预加载
@Service
public class UserService {
@Cacheable(value = "users", key = "#root.methodName")
public List<User> getAllFixedData() {
return userRepository.findAll(); // 首次调用会写入缓存
}
}注意
- 推荐方案:使用 CommandlineRunner 或 @PostConstruct 在启动时主动加载数据到Redis,确保缓存立即可用。
- 注解补充:@Cacheable 适用于懒加载场景,但需结合首次调用触发。
- 注意事项:确保实体类实现 Serializable 接口,并正确配置 RedisTemplate 的序列化方式.
WebSocket知道吗?如果让你设计一个IM 协议,你会考虑什么?
WebSocdket是一种基于 TCP的双向通信协议,它允许服务端主动推送数据给客户端,解决了 HTTP轮洵的效率问题,主要是通过一次HTTP升级握手(Upgrade 请求)建立持久连接,之后双方随时互发数据
如果让我来设计一个 IM 协议,我主要会考虑以下几点:
- 先选择高效传输层,比如 WebSocket
- 然后设计一个轻量可扩展的消息结构,使用JSON或 Protocol Buffers 格式
- 比如消息添加 device id 字段标识发送设备,便于多端同步。
- 消息头包含版本,支持协议升级和向后兼容。
- 格式里面也需要预留扩展字段,比如JSON加 ext:{} / Protobuf加repeated bytes extensions 等
- 确保消息的可靠性,比如 ACK 确认、重试、离线存储等
- ACK 确认:接收方收到消息后回复{"type":"ack”,"msg id":"123456"}
- 离线存储:用户不在线时存到 Redis/MongoDB,上线后推送
- 重传机制:发送方未收到 ACK时,5s后重发(最多3次)
- 消息排序:客户端通过消息ID和时序保证展示顺序(如 Snowflake lD 含时间戳)
- 还可以考虑优化弱网体验,比如用心跳保活、消息压缩等
- 心跳保活:每 30 秒发送{"type":"ping”}防空闲连接被断开
- 弱网适应:动态调整心跳间隔(如弱网时改为 10秒一次)
- 消息压缩:对文本用 GZIP,图片视频用专用算法(如 WebP/H.265)
- 还需要考虑安全性,使用 TLS 加密传输,对敏感信息二次加密
让你设计一个 RPC 框架,怎么设计?
先直接跟面试官说下
RPC 框架基础的核心点其实就这么几点:
- 动态代理(屏蔽底层调用细节)
- 序列化(网络数据传输需要扁平的数据)
- 协议(规定协议,才能识别数据)
- 网络传输(I/O模型相关内容,一般用 Netty 作为底层通信框架即可)
注意,上面加粗的其实二字,一定要说,要注意语气,要显得你游刃有余,低调奢华。
这属于 RPC 框架的基础,生产级别的框架还需要注册中心作为服务的发现,且还需提供路由分组、负载均衡、异常重试、限流熔断等其他功能说到这就可以停下了,然后等面试官发问,正常情况下他会选一个点进行深入探讨,这时候我们只能见招拆招了
下面我们来深入剖析下 RPC,从根上理解它。
RPC 全称是 Remote Procedure Cal ,即远程过程调用,其对应的是我们的本地调用。远程其实指的就是需要网络通信,可以理解为调用远程机器上的方法,那可能有人说我用 HTTP 调用不就是远程调用了,那不也叫 RPC了?
不是的,RPC 的目的是:让我们调用远程方法像调用本地方法一样无差别。来看下代码就很清晰,比如本来没有拆分服务都是本地调用的时候方法是这样写的:
public String getSth(String str) {
return yesService.get(str);
}如果 yesSerivce 被拆分出去,此时需要远程调用了,如果用 HTTP 方式,可能就是
public String getSth(String str) {
RequestParam param = new RequestParam();
......
return HttpClient.get(url, param,.....);
}此时需要关心远程服务的地址,还需要组装请求等等,而如果采用 RPC 调用那就是
public String getSth(String str) {
// 看起来和之前调用没差?哈哈没唬你,
// 具体的实现已经搬到另一个服务上了,这里只有接口。
// 看完下面就知道了。
return yesService.get(str);
}所以说 RPC 其实就是用来屏蔽远程调用网络相关的细节,使得远程调用和本地调用使用一致,让开发的效率更高。
在了解了 RPC 的作用之后,我们来看看 RPC 调用需要经历哪些步骤。
RPC 调用基本流程
动态代理
按上面的例子来说,yesService 服务实现被移到了远程服务上,本地没有具体的实现只有一个接口。那这时候我们需要调用 yesservice.get(str),该怎么办呢?
我们所要做的就是把传入的参数和调用的接口全限定名通过网络通信告知到远程服务那里,然后远程服务接收到参数和接口全限定名就能选中具体的实现并进行调用。业务处理完之后再通过网络返回结果,这就搞定了!
不过我们知道 yesService 就是一个接口,没有实现的,所以这些操作是怎么来的?是通过动态代理来的,RPC 会给接口生成一个代理类,所以我们调用这个接口实际调用的是动态生成的代理类,由代理类来触发远程调用,这样我们调用远程接口就无感知了。
动态代理想必大家都比较熟悉,最常见的就是 Spring 的 AOP 了,涉及的有 JDK 动态代理和 cglib。
在 Dubbo 中用的是 Javassist,至于为什么用这个其实梁飞大佬已经写了博客说明了。他当时对比了 JDK 自带的、ASM、CGLIB(基于ASM包装)、Javassist。经过测试最终选用了Javassist.
梁飞:最终决定使用JAVAASSIST的字节码生成代理方式。
虽然ASM稍快,但并没有快一个数量级,而 Javassist 的字节码生成方式比ASM方便、JAVASSIST只需用字符串拼接出lava源码,便可生成相应字节码,而ASM需要手工写字节码
可以看到选择一个框架的时候性能是一方面,易用性也很关键,
说回 RPC,现在我们知道动态代理屏蔽了 RPC 调用的细节,使得用户无感知的调用远程服务,那调用的细节有哪些呢?
序列化
像我们的请求参数都是对象,有时候是定义的 DTO,有时候是 Map ,这些对象是无法直接在网络中传输的。你可以理解为对象是“立体”的,而网络传输的数据是“扁平”的,最终需要转化成“扁平”的二进制数据在网络中传输。

你想想,各对象分配在内存不同位置,各种引用,这看起来是不是有种立体的感觉?最终都是要变成一段01组成的数字传输给对方,这种就01组成的数字看起来是不是很“扁平”?
把对象转化成二进制数据的过程称为序列化,把二进制数据转化成对象的过程称为反序列化。
当然如何选择序列化格式也很重要。
比如采用二进制的序列化格式数据更加紧凑,采用JSON 等文本型序列化格式可读性更佳,排查问题比较方便还有很多序列化选择,一般需要综合考虑通用性、性能、可读性和兼容性。
RPC 协议
刚才也提到了只有二进制数据才能在网络中传输,那一堆二进制在底层看来是连起来的,它可不会管你哪些数据是哪个请求的,那接收方得知道呀,不然就不能顺利的把二进制教据还原成对应的一个个请求了。于是就需要定义一个协议,来约定一些规范,制定一些边界使得二进制数据可以被还原。
比如下面一串数字按照不同位数来识别得到的结果是不同的。

所以协议其实就定义了到底如何构造和解析这些二进制数据。
我们的参数肯定比上面的复杂,因为参数值长度是不定的,而且协议常常伴随着升级而扩展,毕竟有时候需要加一些新特性,那么协议就得变了。
一般 RPC 协议都是采用协议头+协议体的方式。
协议头放一些元数据,包括:魔法位、协议的版本、消息的类型、序列化方式、整体长度、头长度、扩展位等。
协议体就是放请求的数据了。
通过魔法位可以得知这是不是咱们约定的协议,比如魔法位固定叫 233 ,一看我们就知道这是 233 协议。
然后协议的版本是为了之后协议的升级。
从整体长度和头长度我们就能知道这个请求到底有多少位,前面多少位是头,剩下的都是协议体,这样就能识别出来,扩展位就是留着日后扩展备用。
说白了就是 解决TCP粘包的问题:粘包问题如何解决?、tcp粘包
Dubbo 协议:

可以看到有 Magic 位,请求ID,数据长度等等
网络传输
组装好数据就等着发送了,这时候就涉及网络传输了。网络通信那就离不开网络 1O 模型了。
网络 IO 分为四种模型,具体的可以啊看这篇文章:IO模型
一般而言我们用的都是 IO 多路复用,因为大部分 RPC 调用场景都是高并发调用,IO 复用可以利用较少的线程 hold 住很多请求
一般 RPC 框架会使用已经造好的轮子来作为底层通信框架。例如 Java 语言的都会用 Netty ,人家已经封装的很好了,也做了很多优化,拿来即用,便捷高效。
总结一下
服务调用方,面向接口编程,利用动态代理屏蔽底层调用细节将请求参数、接口等数据组合起来并通过序列化转化为二进制数据,再通过 RPC 协议的封装,利用网络传输到服务提供方。
服务提供方根据约定的协议解析出请求数据,然后反序列化得到参数,找到具体调用的接口,然后执行具体实现,再返回结果。
这里面还有很多细节。比如请求都是异步的,所以每个请求会有唯一 1D,返回结果会带上对应的 ID, 这样调用方就能通过 ID 找到对应的请求塞入相应的结果.有
当然还有很多细节,可以关注 dubbo系列文章
真正工业级别的 RPC
以上提到的只是 RPC 的基础流程,这对于工业级别的使用是远远不够的。
生产环境中的服务提供者都是集群部署的,所以有多个提供者,而且还会随着大促等流量情况动态增减机器。因此需要注册中心,作为服务的发现。
调用者可以通过注册中心得知服务提供者们的IP 地址等元信息,进行调用。
调用者也能通过注册中心得知服务提供者下线。
还需要有路由分组策略,调用者根据下发的路由信息选择对应的服务提供者,能实现分组调用、灰度发布、流量隔离等功能.
还需要有负载均衡策略,一般经过路由过滤之后还是有多个服务提供者可以选择,通过负载均衡策略来达到流量均衡。
当然还需要有异常重试,毕竟网络是不稳定的,而且有时候某个服务提供者也可能出点问题,所以一次调用出错进行重试,减少业务的损耗。
还需要限流熔断,限流是因为服务提供者不知道会接入多少调用者,也不清楚每个调用者的调用量,所以需要衡量一下自身服务的承受值来进行限流,防止服务崩溃。而熔断是为了防止下游服务故障导致自身服务调用超时但塞堆积而崩溃,特别是调用链很长的形种,影响很大,比加A=>B=>C=>D=>E,然后E出了故障,你看ABCD四个服务就傻等着,慢慢的资源就占满了就崩了,全崩。
让你设计一个短链系统,怎么设计?
先说一下回答思路:
- 简单描述下短链原理
- 后端设计
- 补充跳转设计
一个小小短链其实融合了很多知识点,能较为全面的考察一个候选人的综合实力
为什么需要短链?
一般短链会用在短信场景,因为短信有字数限制,超过一定字数收不一样,所以太长的连接不合适。再比如一些社交媒体平台对字数也会有限制。还有一些二维码,如果 url 太长,生成的码也会比较复杂,比较难扫。
原理
原理:在浏览器输入短链后,请求打到短链服务,短链服务会根据 url 找到对应的长链重定向到长链地址,此时浏览器就会跳转网页定位到真正的地址。所以本质原理就是短链服务器根据 url 定位到真正地址,然后通过重定向实现跳转。
后端设计
后端的主要功能是存储短链和长链的对应关系,并且能快速通过短链找到长链.
首先需要先生成短链,假设短链的域名是 seven97.top
- 可以通过数据库自增 id 作为短链,往数据库插入一条长链,对应就会得到一个 id
- 如果用户访问了
seven97.top/1,解析得到1,通过主键就能定位到数据库记录,得到长链https://seven97.top/1长链,这个方式很简单,通过主键查询也很快。
如果面试官问这样的方式有什么缺点,你再说:一旦短链量变多,自增id 会变成很大,比如 99999999999,这样短链也不短了,而且数字有规律性,容易被人遍历出来。没问就不用说。
哈希算法
可以通过hah算法将长链进行hash计算,得到固定的长度,比加通过 md5计算可以得到固定的128bit 数据,还有别的哈希函函数,比加 MurMurHash,它既可以生成128 bit也可以生成32bit,不过32bit相比 128 bit生成速度更慢,且hash 碰撞的概率更高。
这里再提一嘴 MurMurHash 128bit 版本的速度是 md5 的十倍。
还有 crc32 ,得到的就是 32 位的哈希值,运算速度和 md5 差不多。
最终的数据库表结构的设计如下字段:
- id:主键
- short_url:短链
- long_url:原始长 URL
- user_id:用户 ID(如果需要关联用户)
- created_at:创建时间
- updated_at:更新时间
短链字段需要建立索引,因为很常见的查询就是通过短链得到长链。
跳转设计
我们已经了解到通过短链得到长链的过程,那么浏览器具体是如何在输入短链后自动跳到长链地址的呢?
答案就是重定向。这里就需要涉及到 HTTP 的知识点,服务器返回 301 或者 302 状态码,然后在 location 上写上长链的地址,浏览器就会自动识别动作,进行跳转
这两个状态码还是有区别的:
- 301表示永久重定向,即浏览器会默认缓存这次跳转的信息,下次用户在浏览器访问这个短链,浏览器不需要请求短链服务,会自动跳转到长链地址。
- 302 表示临时重定向,即浏览器不会缓存这次跳转信息,用户每次访问这个短链,都需要请求短链服务得到长链。
区别就是 301 可以降低短链服务器压力,因为后续用户访问都不需要清求短链后端服务,而 302 则需要每次访问,但是这样一来可以统计短链访问次数,做一些分析。
扩展
如果数据量大了,一张表存储所有短链数据就会有性能问题,因此需要分库分表
如果是利用自增 ID 转换得到短链信息,在分库分表场景就会出现重复ID的情况,因此可以引入全局发号器来实现全局唯一 ID 分配,比如唯一 ID 可以利用雪花算法生成,
然后通过全局 ID 转化的短链数据作为分表的键即可,因为查询肯定是通过短链来查的。
还有哈希方法可能会导致哈希冲突,即不同的长链可能会生成一样的短链,我们可以将shot_url 作为唯一索引,这样就能保证唯一性,如果插入报错,则可以简单在长链后面拼个随机数,重新进行hah,这样就能避免重复了。
还可以引入缓存,比次我们双十一做了一个营销活动,给很多用户推送了短信,此时肯定会有很多用户访问这个短信内的短链,此时我们就可以将短链相关信息放在缓存中,不需要查数据库,利用缓存提高性能。
让你设计一个分布式 ID 发号器,怎么设计?
一般在分库分表场景,就会有分布式 ID的需求,因为需要有一个唯一标识来标记一个订单或者其他类似的数据等。全局唯一ID有很多种实现,例 UUID,优势就是本地生成,很简单,但它是无序的,如果需要将唯一ID作为主键,则 UUID不合适,首先是太长了,其次无序插入会导致数据页频繁分裂,性能不好。在回答这个面试题的时候可以先提下 UUID,简单说下优缺点 (UUID 的缺点其实侧面能体现出你对 MySQL的了解,这都是小心机呀)
常见的分布式 ID 实现有两种:
1)雪花算法
2)基于数据库
雪花算法
雪花算法有 64bit,实际就用到了 63bit,最前面有一个 1bit 没用,图中就没画了。
其中 41bit是时间戳,10bit是机器ID(可以表示1024台机器,如果有机房的划分,可以把5bit分给机房号,剩下5bit 分给机器)。最后 12bit是自增序列号,12bit 可以表示2的12次方个ID,
可以看到,以时间打头可以保证趋势是有序性,其中分配了机器号避免了多机器之间重复ID 的情况,后面的自增序号使得理论上每台机器每毫秒都可以产生2的12 次方个 ID。
简述优点:
- 分布式 ID 从整体来看有序的。
- 简单、灵活配置,无序依赖外部三方组件。
缺点:
- 依赖时钟,如果发生时钟回拨,可能会导致重复ID。
常见的 hutool 就有提供了雪花算法工具类。
面试官可能会问雪花算法的机器 ID 如何动态配置,因为现在机器都是动态扩容部署,机器数都是不固定的,如果机器 ID 没配置好,容易导致冲突。可以借助 Redis 或者 zookeeper 来实现机器 ID 的分配。redis 的执行是单线程的,机器启动时候调用 redis incr 即可得到自增 id ,可将这个 id 作为机器 ID;zookeeper 的使用也很简单,机器启动时候可以利用 zookeeper 持久顺序节点特性,将注册成功的顺序号作为机器 ID。
基于数据库
对 MySQL 来说,直接利用自增 id 即可实现。
REPLACE INTO table(bizTag) VALUES ('order');
select last_insert_id();将 bizTag 设为唯一索引,可以填写业务值(也可以不同业务多张表),REPLACE INTO 执行后自增 ID会+1、通过 last insert id 即可获得自增的 ID)
优点:简单、利用数据库就能实现,且ID 有序。
缺点:性能不足。
可以利用 auto_increment_increment 和 auto_increment_offset 实现横向扩展
比如现在有两台数据库,auto_increment_increment都设置为2,即步长是2,第一台数据库表 auto_increment_offset 设置为1,第二台数据库表 auto_increment_offset 设置为 2,这样一来,第一台的 ID 增长值就是 1、3、5、7、9.第二台的 ID 增加值就是 2、4、6、8、10。
这样也能保证全局唯一性,多加几台机器弥补性能问题,只要指定好每个表的步长和初始值即可。不过单调递增特性没了,且加机器的成本不低,动态扩容很不方便。
这里我们可以思考下,每次操作数据库就拿一个ID,我们如果一次性拿 1000 个,那不就大大减少操作数据库的次数了吗?性能不就上去了吗?重新设计下表,主要字段如下:
- bizTag: 业务标识
- maxld: 目前已经分配的最大ID
- step: 步长,可以设置为 1000 那么每次就是拿 1000 ,设置成 1w 就是拿 1w 个
每次来获取 ID 的 SQL如下:
UPDATE table SET maxId = max_id + step WHERE bizTag = xxx
SELECT maxId, step FROM table WHERE biz_tag = xxx这其实就是批量思想,大大提升了ID 获取的性能。
到这里可能面试官会追问,假设业务并发量很高,此时业务方一批ID刚好用完后,来获取下一批ID,因为当前数据库压力大,很可能就会产生性能抖动,即卡了一下才拿到ID,从监控上看就是产生毛刺这样怎么处理?
其实这就是考察你是否有预处理思想,如果你看过很多开源组件就会发现预处理的场景很多,例RocketMQ commitlog文件的分配就是预外理,即当前 commitlog 文件用完之前,就会有后台线程预先创建后面要用的文件,就是为了防止创建的那一刻的性能抖动。
同理,这个场景我们也可以使用预处理思想
发号器服务可以本地缓存两个buffer,业务方请求ID每次从其中一个buffer里取,如果这个buffer发现ID已经用了20% (或者另外的数量),则可以起一个后台线程,调用上面的SQL语句,先把下一批的ID 放置到另一个bufer中
当前面那个 buffer ID 都用完了,则使用另一个 buffer 取号,如此循环使用即可,这样就能避免毛刺问题
将 ID 放在本地缓存性能好,即使服务重启了也没事,无非就是中间空了一点点 ID 罢了,整体还是有序的。
一些关键点
雪花算法面试官可能会追问如果时钟回拨了怎么办,理论上可以存储上一次发号的时间,如果当前发号的时间小于之前的发号时间,则说明时钟回拨,此时拒绝发号,可以报警或者重试(重试几次时间可能就回来了)。数
据库方案如果面试官说数据库故障怎么办?理论上数据库故障了其实很多业务都无法执行下去。这属于不可抗柜因素,但是我们有本地缓存,可以将 step 设置大一些,例qps最高时候的600 倍,这样至少有 10分钟的缓冲时间,可能数据库就恢复了,其次数据库可以做主从,但是主从会有复制延迟,导致 maxId 重复,这里可以采取和雪花算法对抗时钟回拔一样的套路,服务记录上次 maxId,如果发现,maxId 变小了,则再执行一次 update.
还有一点,数据库实现的ID是完全连续的,如果用在订单场最,竟对早上下一单,晚上下一单,两单一减就知道你今天卖了多少单,所以很不安全,因此这种|D不适合用在这种场景(再比如文章的id容易被爬虫简单按序一次性爬完)。
这一套如果跟面试官说下来,我相信这场面试你肯定稳了,整体设计没问题,还有很多性能方面的考虑并且还想到了安全性问题。
让你设计一个购物车功能,怎么设计?
购物车主要功能包括:加购、商品列表展示和结算下单。
针对这几个功能,购物车至少需要包括:商品SKUID、数量、加购时间和勾选状态,具体的图片、标题、描述等可以实时获取,购物车不存储。
针对加购,需要考虑用户是否登录:
- 未登录用户:用Cookie 或本地存储(如LocalStorage)暂存购物车数据,避免丢失。
- 登录用户:数据同步到数据库(如MySQL),这样就支持多端(PC、APP)同步。
商品列表展示,对用户是否登录情况下也有所区别:
- 未登录用户:Cookie 或本地存储(如LocalStorage)采用json格式存储即可
{
"cart": [
{
"SKUID": 123,
"timestamp": 1747036940,
"count": 1,
"selected": true
},
{
"SKUID": 456,
"timestamp": 1747036941,
"count": 5,
"selected": false
}
]
}- 登录用户:直接从数据库查询,注意 userid 字段需要建立索引,优化查询
CREATE TABLE cart (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
sku_id BIGINT NOT NULL,
count INT DEFAULT 1 COMMENT '数量',
selected TINYINT DEFAULT 1 COMMENT '是否选中结算',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
KEY idx_user(user_id)
);结算下单后,从购物车中移除selected=tue的商品,这个步骤可以异步操作,能接受一定的延时,因为一般来说用户下单后不会立刻访问购物车,而且即使访问了,数据还在影响不大。
不过现在有些产品的加购设计要求用户必须登录,比如京东网页版,点击加入购物车之后,自动跳转到登录页。
让你设计一个文件上传系统,怎么设计?
这种题目都是开放性的,面试过程中也不奢望聊出所有的设计细节,仅仅需要抛出一些大致的设计需求与要点,然后简单的方案实现思路即可。关于文件上传系统有几个最主要的核心点需要解决:
- 如何支持超大文件上传
- 避免重复文件存储,节省空间
- 限流问题
大文件上传
假设有个10G的文件需要上传,正常情况下是将文件转成流传到后端,如果不做任何处理,前端一直传,后端存储这些流直到传递完成,后端非常容易内存溢出,多来几个人,后端的内存至少需要几十个G,一船的后端服务都没有这么大的内存。
并且一旦出现网络抖动或者其他情况,前端传输失败,前面传的都白费了。所以必须需要将大文件进行切割传输,即切块传输,所谓的切块很容易理解,举个很简单的例子,假设一个视频 60 分钟,我们将它切成 60 个1分钟的视频,合起来不就是完整的视频了? 后端分别存储切割的小视频,不需要等待所有文件传输完成合并存储,等到时候需要下载的时候,分块转成流给前端就好了。
总结一下:大文件需要前端分块传输给后端,后端分块存储,后面下载的时候,后端按序将分块文件给予前端即可。
避免存储重复文件
对于这点,很多同学都会想到用文件名判重,文件名相同的被识别为一个文件,这对于文件系统来说明显是不合理的。那应该用什么方式呢?有个叫哈希摘要的东西,也就是计算文件的 md5(或者其他 hash 算法),得到摘要,对比两个文件的摘要,如何摘要一致就可以认为是同一份文件。
摘要在文件场景非常常见,例如 jdk 的下载就会附上摘要,用来判别我们下载的文件是否被篡改,如果摘要一致说明文件没有被篡改过。
限流问题
文件上传需要占用的资源挺多,内存、磁盘、带宽等等,所以需要做一定的限制。
比如限制文件的最大值,防止恶意超大文件上传。
限制每天用户上传的次数、上传的频次间隔、上传的总文件大小量。
利用令牌桶或其他限流算法,限制同一时刻的上传用户数,防止后端压力过大和内存溢出问题。
监控后端内存,内存超过一定阈值后报警通知,灵活配置限流,保护后端系统安全。
切块以及存储简要流程
可以将文件切成 2m 每块,分块文件存储至服务器,分块记录存储到 redis 中,key 的设置可以是 userid +uuid(标明这次的文件)+filename+seq(顺序)之所以利用 redis 是因为性能高,其次可以设置过期时间,因为大文件上传存在传一半用户觉得太慢,取消上传,这时候之前上传的切块文件都应该被清理。而 redis 可以自动过期 key ,后续监听到在这个 key 没了,就可以清理之前上传的无用切块文件,节省空间。每次切块上传,都可以利用 md.upddle 更新 md5 摘要(固定大小不会因为大文件挤出内存),等上传完毕就可以利用 md.digest 获取文件摘要,此时将 redis的分块记录、切块文件数量、总大少、摘要等一切信息都落库即可,
上传文件的时候,前端将文件摘要信息传递至后端,后端从数据库查找是否有一致摘要,如果有则说明文件已存在,直接保存相关的信息,然后返回前端上传成功即可。大致方案如何,面试中还是需要具体情况具体分析,每个面试官询问的角度都不同,如果你有实力,则投其所好,如果你有些地方比较强,则引导面试言询问你擅长的方向。
让你设计一个线程池,怎么设计?
这种设计类问题还是一样,先说下理解,表明你是知道这个东西的用处和原理的,然后开始 阐述。
基本上就是按照现有的设计来说,再添加一些个人见解。
线程池讲白了就是存储线程的一个容器,池内保存之前建立过的线程来重复执行任务,减少创建和销毁线程的开销,提高任务的响应速度,并便于线程的管理。
我个人觉得如果要设计一个线程池的话得考虑池内工作线程的管理、任务编排执行、线程池超负荷处理方案、监控。
初始化线程数、核心线程数、最大线程池都暴露出来可配置,包括超过核心线程数的线程空闲消亡配置
任务的存储结构可配置,可以是无界队列也可以是有界队列,也可以根据配置分多个队列来分配不同优先级的任务,也可以采用stealing 的机制来提高线程的利用率。
再提供配置来表明此线程池是 IO 密集还是 CPU 密集型来改变任务的执行策略。
超负荷的方案可以有多种,包括丢弃任务、拒绝任务并抛出异常、丢弃最旧的任务或自定义等等
线程池埋好点暴露出用于监控的接口,如已处理任务数、待处理任务数、正在运行的线程数、拒绝的任务数等等信息。我觉得基本上这样答就差不多了,等着面试官的追问就好。
注意不需要跟面试官解释什么叫核心线程数之类的,都懂的没必要,当然这种开放型问题还是仁者见仁智者见智,我这个不是标准答案,仅供参考。
让你设计一个消息队列,怎么设计?
设计类题目要先从大局上讲出需要设计的东西的重点,然后再等待面试官的继续提问,深挖
回答:
首先我们需要明确地提出消息中间件的几个重要角色,分别是生产者、消费者、Broker、注册中心。
简述下消息中间件数据流转过程,无非就是生产者生成消息,发送至 Broker,Broker 可以暂缓消息,然后消费者再从 Broker 获取消息,用于消费。
而注册中心用于服务的发现包括:Broker 的发现、生产者的发现、消费者的发现,当然还包括下线,可以说服务的高可用离不开注册中心。
然后开始简述实现要点,可以从通信讲起:各模块的通信可以基于 Netty然后自定义协议来实现,注册中心可以利用zookeeper、eureka、nacos等等,也可以像 RoketMQ 自已实现简单的 nameserver(这一句活就都是关键词)
为了考虑扩容和整体的性能,采用分布式的思想,像Kafka一样采取分区理念,一个topic分为多个pardition,并目为保证数据可靠件,采取多副本存储,即 Leader和 follower,根据性能和数据可靠的权衡提供导步和同步的刷盘存储。
并且利用选举算法保证 Leader 挂了之后 follower 可以顶上,保证消息队列的高可用。
也同样为了提高消息队列的可靠性利用本地文件系统来存储消息,并且采用顺序写的方式来提高性能。
可根据消息队列的特性利用内存映射、零拷贝进一步的提升性能,还可利用像 Kafka 这种批处理思想提高整体的吞吐,至此就差不多了,该说的要点说的都差不多了,面试官心里已经想,这人好像有点东西。
还有一点需要注意:在说各设计要点的时候也要注意停顿,要留机会给面试官插话,让面试官充分参与你的设计
让面试官有参与感,让他感觉经过他的引导这个设计才逐步地完善。让面试成为一场技术交流,这是面试的最高境界
让你实现一个分布式单例对象,如何实现?
所谓的单例一般指的是一个进程中一个类对应只有一个实例对象,也就是进程唯一
而分布式,不过是一个机器部署多个服务,还是多个机器部署,本质上就是多进程,所以所谓的分布式单例指的是这个实例对应需要在多进程中保持唯一按照这个思路,我们仅需控制同一时刻,只会有一个进程使用这个单例对象即可,而分布式场景下的分布式锁就很容易实现这个功能.
多个进程竞争分布式锁,谁抢到锁,谁此时就可以使用这个单例对象,用完之后释放这个对象,并且释放锁,这样不就保证多进程中实例对象唯一了吗?
所以,我们需要在三方外部存储这个单例对象,每次进程用完单例对象后,再将对象的数据写回外部存储中,这样就能保证多个进程对这个单例对象的修改都同步,状态一致
分布式锁可以用 redis 实现,三方外部存储也可以用 redis 实现,
总结下:每个进程使用这个类的时候,争抢分布式锁,如果抢到则从redis获取这个数据,反字列化或一个对象使用,使用完之后,将对象数据再,序列化存储到redis 中,覆盖之前的数据,最终释放锁。
如果项目需要你实现敏感词过滤功能,如何实现?
回答重点
最简单的肯定是字符串匹配,但是这种仅适用文本较少的情况,通过使用 indexof、contains方法即可实现。
比较常见且高效的方法是 基于 Trie 树的 DFA 算法,它将 Trie 树(字典树)的存储结构与 DFA(确定有限自动机)的状态转移机制相结合!
Trie 树按字符路径存储敏感词,共享前缀节点以节省空间。
DFA 则通过状态转移函数在树中快速匹配文本,遇到标记节点(敏感词结尾)即完成识别。这个算法只需遍历一次文本,时间复杂度为 O(n)。
实际上,大部分公司都会用云厂商提供的敏感词过滤服务,不会自己去实现,说完原理后,可以提一嘴这个
扩展知识
Trie 树(字典树)
Trie 树是一种树形结构,常用于高效存储和检索字符串集合。
它的核心特点是:
- 根节点不存储字符,除根节点外的每个节点都存储一个字符。
- 从根到某节点的路径上的字符连接起来,即为该节点对应的字符串。
- 每个节点可以有多个子节点,子节点的字符各不相同。
- 用一个标记(如 isEnd )表示该节点是否为一个字符串的结尾。
看下示例,假设我们有三个敏感词:["he”,"she”,"his"],构建的 Trie 树结构如下:
root
├── h
│ └── e (isEnd=true)
│ └── i
│ └── s (isEnd=true)
└── s
└── h
└── e (isEnd=true)DFA(确定有限自动机)
DFA 是一种计算模型,它由以下部分组成:
- 状态集合:每个状态代表 Trie 树中的一个节点。
- 输入字母表:通常是字符集(如 ASCII 字符)
- 状态转移函数:根据当前状态和输入字符,确定下一个状态。
- 初始状态:Trie 树的根节点。
- 接受状态:Trie 树中标记为 isEnd 的节点。
DFA 的工作流程如下:
- 从初始状态(根节点)开始。
- 逐个读取输入字符串中的字符,根据当前状态和字符进行状态转移。
- 如果转移到接受状态,则匹配到一个字符串。
- 如果无法转移(即没有对应的子节点),则匹配失败,回到初始状态继续处理后续字符
基于 Trie 树实现 DFA,每个节点就是一个状态,状态转移就是在树中从父节点移动到子节点。
执行过程示例
需要待检测的文本是: ushers
匹配过程如下:
- 位置 0(u):根节点没有子节点 u,匹配失败,继续处理下一个字符。
- 位置 1(s):根节点 → 子节点 s(状态转移),继续处理后续字符 h。
- 位置 2(h):当前节点 s → 子节点 h,继续处理后续字符 e。
- 位置 3(e):当前节点 h → 子节点 e(isEnd-true ,匹配到敏感词 she,继续处理后续字符 r,但当前节点 e 没有子节点r,匹配结束。
- 结果:从位置1到3匹配到 she ,替换为 *** 。
- 位置 4(r):根节点没有子节点 r,匹配失败,继续处理下一个字符。
- 位置 5(s):根节点 → 子节点 s,继续处理后续字符 s 的下一个字符(无),匹配结束,未形成完整敏感词,
最终结果变为 u***rs
简单提一下,AC 自动机(Aho-Corasick),它会在Trie 树上增加 失败指针,当匹配失败时直接跳转到最长前缀的节点,避免回退,进一步提高效率,。
对于超长文本,可分段并行多线程匹配,提高吞吐量。
如何设计一个秒杀功能?
面试官针对这个问题不指望候选人可以系统地回答出完且可落地的方案。只是想考察候选人是否拥有高并发大流量场景下的处理思路或者说能考虑到的一些关键点。针对秒杀场景,我们需要先和面试官说出以下几个需要解决的问题点:
- 瞬时流量的承接
- 防止超卖
- 预防黑产
- 避免对正常服务的影响
- 兜底方案
然后可以从前后端两个视角向面试官阐述整体的设计点:
首先是前端:
- 利用 CDN 缓存静态资源(秒杀页面的 HTML、CSS、JS 等),减轻服务器的压力
- 客户端限流,在前端随机限流,降低请求量
- 按钮防抖,防止用户重复多次点击发出大量请求
其次是后端:
- Nginx(或其他接入层)做统一接入,负载均衡与流量过滤、限流
- 业务端限流,可以自定义实现本地 guava 限流或利用 sentinel 等
- 服务拆分,将秒杀功能拆分为独立的服务,避免对现有服务产生影响
- 秒杀数据的拆分和缓存,缓存可以使用分布式缓存或本地缓存方案,且需要缓存预热
- 精准地库存扣减,防止超卖发生
- 风控识别黑产,进行流量防控目需要动态黑名单机制
- 验证码、答题等手段预防脚本刷单
- 幂等操作,防止重复下单
- 业务手段降低并发量,例如通过预约、预售。
- 兜底方案,如果服务压力过大或者代码有漏洞,那么关闭秒杀直接返回秒杀结束,降低服务压力及时止损。
瞬时流量的承接
一般情况下,秒杀的流量特性就是持续性短和大。
流量集中在活动即将开始的时候,会有很多用户开始持续性地刷页面。前端资源的访问也需要损耗大量的资源,因此需要利用 CDN 缓存秒杀页面的一些静态资源,将这部分压力给到 CDN 厂商。
并且静态资源放在 CDN 厂商那之后,地理位置也距离用户更近,用户访问也就更快,体验上也更好!

秒杀页面可手动推给 CDN 预热。
秒杀流量还有个特点,就是大部分请求实际都是无效的,因为秒杀的商品库存往往都是个位数,而抢购的用户是其成千上万倍.
假设有 100 万的请求来抢购一台 iPhone,那么需要放这 100 万请求直接打到后端服务吗?显然不需要。
针对这个情况,我们就需要层层过滤请求。例如前面提到的客户端限流,即在前端随机眼流,降低清求量。说的更直白一些即部分用户点击抢购技钮,但是请求都发不到后端,直接前端代码返回秒杀结束。(如果预测量是在太大,可以这样操作,毕竟也是随机的)
如果前端请求发出来了,那么可以利用 nginx 统一接入,针对更大的流量可以在 nginx 前面再加 Ivs。Ivs四层转发清求打到多台 nginx上,nginx 再负载均衡到多台后端服务,且 nginx 有限流功能,例如ip 限流,还可以配置黑名单等等,其实已经可以拦截大量请求流量,请求到达后端服务之前还可以再进行限流,比如使用 sentinel 再拦截一道。
最终请求打到后端服务,涉及到一些读取数据和写数据的操作。如果量级不大且数据库配置高,理论上可以用数据库来承接(数据库层面也是有优化的,后面介绍)。
这时候也可以利用缓存来承接读写,可以用本地缓存或分布式缓存,如 Redis。
最终一个相对而言比较完整的请求链路如下:

库存扣减设计
先看一下正常扣减库存的思路:

这样的设计会有什么问题?并发问题,导致超卖。

此时可以加锁,比如利用数据库的锁,针对这个场景数据库常用的是乐观锁。
update inventory set available_inventory = available_inventory - 1
where sku_id = 1 and available_inventory > 0;如果使用这个语句,在高并发场景下,实际上就会产生热点行问题。
数据库热点行问题
我之前公司基于数据库扣减方案,压观单台机子下单链路的并发只能达到70,单个扣减库存的接口并发只有 200 就把数据库 CPU 压满了。(各公司实际内部业务不同,仅供参考)
我们当时数据库用的是阿里云的 RDS,实际上有一个可落地的优化方案:Inventory hint + Returning。如果你公司本身用的就是阿里云的 RDS,这个改造成本就很低,仅需在 SQL 上填写一些 hint 即可。在SQL表名前加/*+COMMIT ON SUCCESS ROLLBACKON FAIL TARGET AFFECT ROW(1)*/
update /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL
TARGET_AFFECT_ROW(1)*/ inventory
set available_inventory = available_inventory - 1
where sku_id = 1 and available_inventory > 0;Inventory hint 原理简单介绍:
COMMIT ON SUCCESS:当前语句执行成功就提交事务上下文,
ROLLBACK ON FAIL:当前语句执行失败就回滚事务上下文。
TARGET AFFECT ROW(NUMBER):如果当前语句影响行数是指定的就成功,否则语句失败
设置了这几个hint后,当前的语句会按照主键(或唯一键)分组,将相同行的请求修改分为一组,分组后仅组内第一条 SQL 需要抢锁,后续的都不需要申请锁,减少申请锁的流程。然后组内第一条 SOL 已经遍历 B+树查询到数据了,后续组内库存扣减直接改即可,不用再次查询。且组内 SQL都修改完之后,仅需一次分组提交事务即可。根据阿里云介绍,结合 Inventory hint 单行TPS 可达 3.1w:
还可以配合Returning使用:
CALL dbms_trans.returning("*", "update /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL
TARGET_AFFECT_ROW(1)*/ inventory
set available_inventory = available_inventory - 1
where sku_id = 1 and available_inventory > 0;");正常情况下,如果我们 update 扣减了一次库存之后,如果想得知最新的库存,那么需要再执行一次select操作,而 returing,可以直接返回实时的库存,减少一次查询
利用 Returning,我们可以得知实时的库存,发现没库存后,可以直接设置一个标志位,表明秒杀已经结束,快速 fail 请求,降低服务的压力。还有一个 statement queue 我之前没用到,关于这几个 hint 的详情,可以查看这个介绍链接
库存拆分
除了数据库补丁优化,从业务角度,我们可以将库存进行拆分。
上面举例是1个库存,但有时候的秒杀的库存会更多,例如 1000 个库存,此时就可以将这 1000 个库存拆分成 100 个小库存,每个小库存内有 10 个库存。

这样其实就是人为的把热点行拆分了,可以把小库存分散到不同的表或者库中,等于将并发度提升了10 倍
看起来挺简单,实际对于整个库存扣减流程的改造还是挺大的,例如分桶的库存调配、创建库存时分桶的库存分配、表的映射、库的映射等等,
插入库存扣减流水
既然直接 update 有热点行问题,那么就将 update 改为 insert 。
实际上用户的购买从更新库存变成插入流水,然后异步定时将流水库存同步到剩余库存中。
这个手段确实避免了热点行的问题,但插入数据不好控制总的数据量,容易导致超卖。
可以跟面试官提一下这个方案,跟他说清这个方案是有超卖的问题。表明你知道这个思路,也知道这个方案的缺点。
这个思路实际上在非限制库存的热点行场景可以使用。
缓存预减库存
利用缓存来承接热点数据是很多人都熟知的方案,例如使用 Redis。可以将库存提前同步到 Redis 中,先使用 redis +lua 脚本控制库存的扣减,减少数据库的访问。lua 脚本的内容实际上很简单,我用文字来描述一下:
- 根据商品 key 获取库存
- 如果有则库存-1,返回新库存
- 如果没库存,则返回没库存
redis + lua 可以保证操作的原子性,且性能足够优秀,因此是一个非常高效的库存扣减方案,然后 redis 扣减完毕之后,可以发送一个异步消息(消息队列削峰填谷),后端服务异步消费把数据库中的库存给扣了,实现最终一致性。

看到这肯定有同学会问:“redis 操作成功后,mg发送失败怎么办?"
因此,我们还需要一个准实时对账机制,lua 脚本内不仅要扣减库存,还需要利用 zset 增加流水,score 设置为时间,定时拉取一段时间流水记录比对数据库的库存是否一致,如果不一致则补偿。
至于本地缓存,理论上性能更高,但是方案设计上会更复杂,因为库存被分配到多个应用中。需要在秒杀预热的时候,给后端服务预分面好库存,然后应用各自承接库存扣减,也需要做好对账,防止意外的发生。
库存为0后
可以使用Map为商品库存添加内存标记,减少Redis缓存的访问次数
预防黑产
大一点的公司都会有风控机制,借助一些算法对用户的来源、行为数据等等进行分析,如果发现不法分子,则将其加入到黑名单中。
脚本抢购实际上可以用验证码、答题等机制拦截,并且这种机制也可以打散用户的请求,降低瞬时流量高峰。
幂等设计
可以看这题: 如何避免用户重复下单(多次下单未支付,占用库存)
业务手段
预约:例如 Nike 设计就是抢购,预约有一个比较长的时间段,例如 15 分钟。然后预约通过后等待最终抽签结果即可。这样的设计通过一段时间的预约,可减少瞬时的压力,再异步通过后台实现抽签来间接解决秒杀的问题。
预售:例如现在的电商活动都搞定金预售。通过下定让用户感觉这个商品已经到手了,不需要再等到双十一或者 618 零点准时抢购,均摊了请求,减少准点抢购的压力。避免对正常服务的影响
大部分公司秒杀都是和正常服务糅合在一起的,没有做区分。如果成本允许,且为了避免对正常业务产生影响,则可以将秒杀单独剥离出一套,独立域名、独立服务器部署等,不过这样实现起来其实很麻烦,最终的数据还是需要同步的正常服务中的,成本比较大。
兜底方案
或许在真正的业务中,很少有人会做兜底方案,都仅考虑正向业务,但是兜底确实很重要所以在业务上的设计我们要尽量考虑异常极端情况,设计一个简单的兜底也比没兜底好。
在面试中,那就得疯狂兜底!向面试官展示出你的方案面面俱到!
针对秒杀,其实最简单的方案就是加个开关:关闭秒杀,直接返回秒杀结束
这个兜底是为了避免极端情况发生,严重影响正常业务的进行或产生资损。
因为秒杀对用户而言本身是一个可以接受失败的场景,没抢到很正常,只要用户来参加我们的活动,营销目的也达到了,所以在严重影响正常业务进行或者发现代码出现漏洞,被人薅羊毛的情况下,关闭秒杀是最好的选择!