24年11月6日,阿里巴巴旗下的Java Excel工具库EasyExcel宣布,将停止更新,未来将逐步进入维护模式,将继续修复Bug,但不再主动新增功能。
EasyExcel 是一款知名的 Java Excel 工具库,由阿里巴巴开源,作者是玉箫,在 GitHub 上有 30k+ stars、7.5k forks。 据了解,EasyExcel作者玉箫去年已经从阿里离职,开始创业,也是开源数据库客户端 Chat2DB 的作者。
尽管 EasyExcel 已经不再维护,但其也不失为一个强大且优秀的工具框架,这里我们就一起看一下如何使用 EasyExcel实现百万数据的导入导出。
简介
在日常的开发工作中,Excel 文件的读取和写入是非常常见的需求,特别是在后台管理系统中更为频繁,基于传统的方式操作excel通常比较繁琐,EasyExcel 库的出现为我们带来了更简单、更高效的解决方案。本文将介绍 EasyExcel 库的基本用法和一些常见应用场景,帮助开发者更好地利用 EasyExcel 提高工作效率。
代码地址:https://github.com/alibaba/easyexcel
官网地址:Easy Excel 官网 (alibaba.com)
青出于蓝而胜于蓝
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便
16M内存23秒读取75M(46W行25列)的Excel(3.2.1+版本)
当然还有极速模式能更快,但是内存占用会在100M多一点 !

EasyExcel 核心类
EasyExcel 的核心类主要包括以下几个:
- ExcelReader: 用于读取 Excel 文件的核心类。通过 ExcelReader 类可以读取 Excel 文件中的数据,并进行相应的处理和操作。
- ExcelWriter: 用于写入 Excel 文件的核心类。通过 ExcelWriter 类可以将数据写入到 Excel 文件中,并进行样式设置、标题添加等操作。
- AnalysisEventListener: 事件监听器接口,用于处理 Excel 文件读取过程中的事件,如读取到每一行数据时的操作。
- AnalysisContext: 读取 Excel 文件时的上下文信息,包括当前行号、sheet 名称等。通过 AnalysisContext 可以获取到读取过程中的一些关键信息。
- WriteHandler: 写入 Excel 文件时的处理器接口,用于处理 Excel 文件的样式设置、标题添加等操作。
- WriteSheet: 写入 Excel 文件时的 Sheet 配置类,用于指定写入数据的 Sheet 名称、样式等信息。
这些核心类在 EasyExcel 中承担了不同的角色,协作完成了 Excel 文件的读取和写入操作。开发者可以根据具体的需求和场景,使用这些类来实现 Excel 文件的各种操作。
Alibaba EasyExcel的核心入口类是EasyExcel类,就想我们平时封装的Util类一样,通过它对excel数据读取或者导出。
技术方案
百万数据导入
以下代码源码点击这里
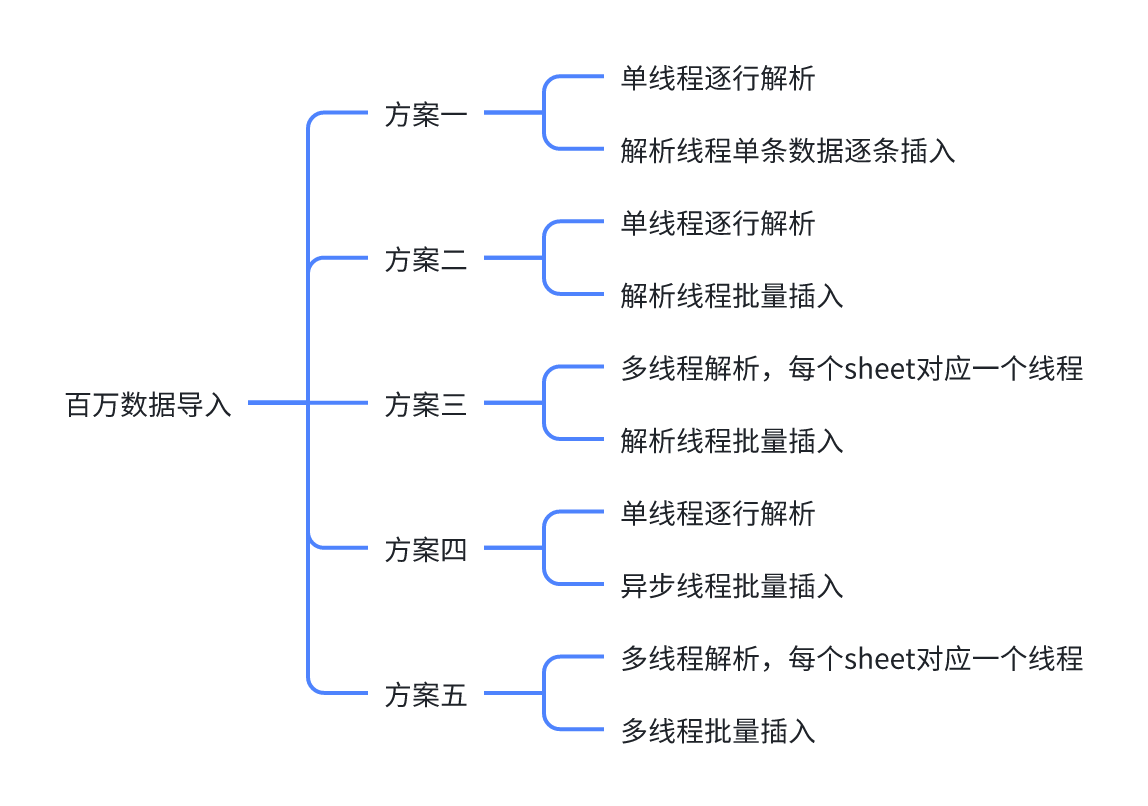
方案一
单线程逐行解析: 使用单个线程顺序地逐行读取 Excel 文件
解析线程单条数据逐条插入:使用解析线程,每读取到一条数据,就立即执行单条插入操作
优点:实现简单,容易调试和维护;适合小数据量的场景。
缺点:效率极低,因为每次插入都要进行一次网络请求和磁盘I/O操作,且没有利用到批量操作的优势。在大量数据的情况下非常耗时。
//方案一,方案二,方案四:单线程逐条解析
public void importExcel(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), Salaries.class, salariesListener).doReadAll();
}EasyExcel解析完之后,都会回调ReadListener方法
@Override
@Transactional(rollbackFor = Exception.class)
public void invoke(Salaries data, AnalysisContext context) {
//方案一:单线程逐行插入
saveOne(data);
}
public void saveOne(Salaries data) {
save(data);
logger.info("第" + count.getAndAdd(1) + "次插入1条数据");
}方案二(推荐)
- 单线程逐行解析:使用一个线程逐行读取 Excel 文件的数据。
- 解析线程批量插入:使用解析线程,将读取到的数据积累到一定数量后,执行批量插入操作
优点:实现相对简单。比单条插入效率高,减少了网络请求和磁盘I/O的次数
缺点:受限于单线程的处理能力,效率不如多线程,并且在解析过程中可能会消耗大量内存,因为需要先将数据读入内存再进行批量插入。
//方案一,方案二,方案四:单线程逐条解析
public void importExcel(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), Salaries.class, salariesListener).doReadAll();
}@Override
@Transactional(rollbackFor = Exception.class)
public void invoke(Salaries data, AnalysisContext context) {
salariesList.get().add(data);
if (salariesList.get().size() >= batchSize) {
saveData();
}
}
public void saveData() {
if (!salariesList.get().isEmpty()) {
saveBatch(salariesList.get(), salariesList.get().size());
logger.info("第" + count.getAndAdd(1) + "次插入" + salariesList.get().size() + "条数据");
salariesList.get().clear();
}
}方案三
- 多线程解析:每个Sheet对应一个线程进行解析,多个线程并行解析不同的Sheet。
- 解析线程批量插入:使用解析的线程,将读取到的数据积累到一定数量后,执行批量插入操作。
优点:多线程解析可以充分利用多核CPU的优势,提高解析速度;批量插入可以减少数据库的事务开销和I/O操作。
缺点:需要考虑多线程之间的数据传输和同步的问题,设计和实现较复杂。可能在解析和插入之间存在性能瓶颈。例如,若插入较快,则需要等待解析完成才可进行插入,因此可用异步线程的方式
//方案三,方案四:多线程解析,一个sheet对应一个线程
public void importExcelAsync(MultipartFile file) {
// 开20个线程分别处理20个sheet
List < Callable < Object >> tasks = new ArrayList < > ();
for (int i = 0; i < 20; i++) {
int num = i;
tasks.add(() - > {
EasyExcel.read(file.getInputStream(), Salaries.class, salariesListener)
.sheet(num)
.doRead();
return null;
});
}
try {
executorService.invokeAll(tasks);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}@Override
@Transactional(rollbackFor = Exception.class)
public void invoke(Salaries data, AnalysisContext context) {
//方案二、三、四、五
salariesList.get().add(data);
if (salariesList.get().size() >= batchSize) {
saveData();
}
}方案四(较推荐)
- 单线程逐行解析:使用一个线程逐行读取 Excel 文件的数据。
- 异步线程批量插入:另开一个线程将数据批量插入到数据库,解析线程可以继续执行后续的解析操作。(可以只使用一个线程,防止多线程插入导致锁竞争的问题)
优点:解析和插入操作分离,可以在解析的同时进行插入,提高效率。
缺点:受限于单线程解析速度,而且需要管理异步操作
//方案一,方案二,方案四:单线程逐条解析
public void importExcel(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), Salaries.class, salariesListener).doReadAll();
}@Override
@Transactional(rollbackFor = Exception.class)
public void invoke(Salaries data, AnalysisContext context) {
salariesList.get().add(data);
if (salariesList.get().size() >= batchSize) {
asyncSaveData1();//异步线程批量插入
}
}方案五(推荐)
- 多线程解析:每个Sheet对应一个线程进行解析,多个线程并行解析不同的Sheet。
- 多线程批量插入:另开多个线程将数据批量插入到数据库。
优点:结合了多线程解析和多线程异步插入的优势,可以最大化利用系统资源,提高数据导入速度。
缺点:实现较为复杂。需要小心处理数据库的并发连接和事务管理,防止引入死锁和性能瓶颈。
//方案三,方案四:多线程解析,一个sheet对应一个线程
public void importExcelAsync(MultipartFile file) {
// 开20个线程分别处理20个sheet
List < Callable < Object >> tasks = new ArrayList < > ();
for (int i = 0; i < 20; i++) {
int num = i;
tasks.add(() - > {
EasyExcel.read(file.getInputStream(), Salaries.class, salariesListener)
.sheet(num)
.doRead();
return null;
});
}
try {
executorService.invokeAll(tasks);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}@Override
@Transactional(rollbackFor = Exception.class)
public void invoke(Salaries data, AnalysisContext context) {
salariesList.get().add(data);
if (salariesList.get().size() >= batchSize) {
asyncSaveData();//多线程批量插入
}
}
public void asyncSaveData() {
if (!salariesList.get().isEmpty()) {
ArrayList < Salaries > salaries = (ArrayList < Salaries > ) salariesList.get().clone();
executorService.execute(new SaveTask(salaries, salariesListener));
salariesList.get().clear();
}
}方案选择
- 数据量较小(如几万条或更少的数据):可以选择方案2(单线程逐行解析;单线程批量插入)或方案4(单线程逐行解析;异步线程批量插入),实现简单且性能足够。
- 数据量较大(如几十万到百万条数据):推荐方案5(多线程解析,每个sheet对应一个线程;异步线程批量插入)。尽管实现复杂,但它能够充分利用系统资源,极大地提升导入效率。
在选择方案4时,需要特别注意以下几点:
- 复杂性增加:方案4引入了异步操作,这意味着需要管理异步线程的生命周期,处理线程同步和可能的并发问题。对于小数据量,这种额外的复杂性可能不值得。
- 性能开销:异步操作可能会带来额外的性能开销,尤其是在线程创建、上下文切换和管理异步队列等方面。如果数据量不大,这些开销可能超过其带来的性能提升。
- 资源利用:对于小数据量,单线程的解析和批量插入可能已经足够快,且能够有效利用系统资源。引入异步操作可能会导致资源管理变得更加复杂,而不一定能带来明显的性能改进。当Excel中只有一个sheet时,只能逐行解析,但是以下几点可以考虑:
- 单线程足够:如果数据量不大,单线程逐行解析配合批量插入已经能够提供足够快的导入速度。
- 简化实现:单线程方案(如方案2)实现起来更简单,更容易调试和维护。
- 性能测试:在没有进行性能测试之前,可能无法确定异步操作是否真的带来了性能上的提升。有时候,简单的同步方案就足够满足需求。
总之,方案4可能在数据量较大时更有优势,因为它可以更有效地利用系统资源,但在数据量不大时,这种优势可能不明显,反而增加了实现的复杂性和维护成本。因此,在选择方案时,需要根据实际的数据量、系统资源和性能需求来做出决策。但若是数据量较大,并且只有一个sheet,只能逐行解析时,较推荐使用方案4。
在选择方案5时,需要特别注意以下几点:
- 线程池管理:使用Java的
ExecutorService来管理解析和插入线程,防止线程过多导致资源耗尽。 - 批量插入大小:适当的批量大小可以提高性能,一般建议每次批量插入500到1000条数据。
- 数据库连接池:配置合理的数据库连接池(如HikariCP),以支持高并发的数据库操作。
- 错误处理和事务管理:确保对于每批数据操作有适当的错误处理和事务管理,以保证数据一致性。
综合考虑性能和实现复杂性,方案5 是处理百万级数据导入的最佳选择,前提是能合理管理多线程和数据库连接。
百万数据导出
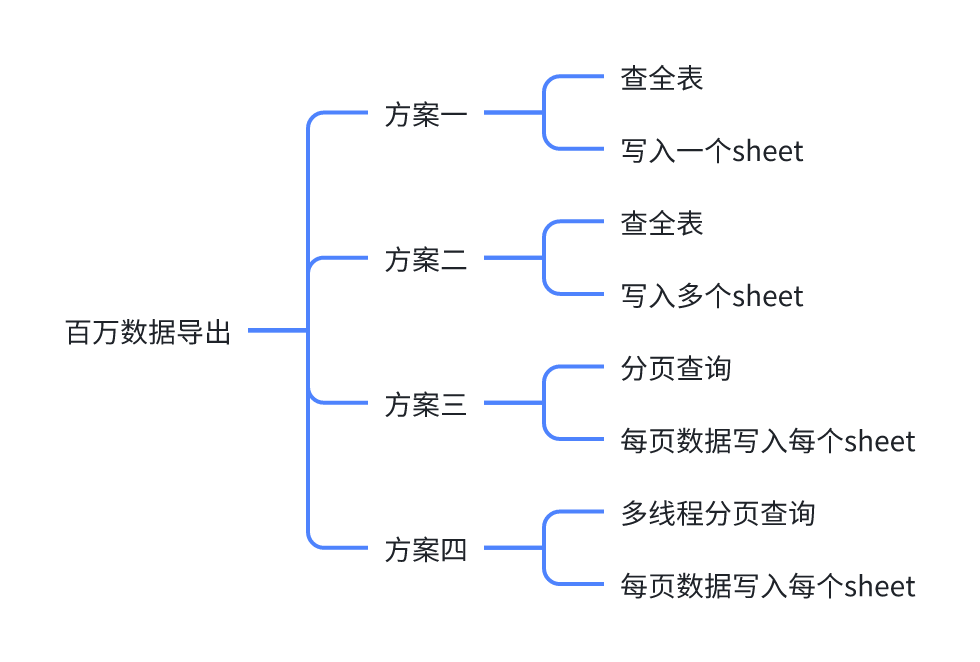
方案一
- 查全表:一次性查询出整个表的数据。
- 写入一个sheet:将所有查询结果写入同一个 Excel sheet 中。
优点:实现简单,逻辑清晰;适用于数据量小的情况。
缺点:
- 性能瓶颈:一次性查询大量数据会占用大量内存。
- Excel 单个 sheet 限制:Excel 对单个 sheet 有行数限制(通常是 1048576 行),超过这个限制会导致问题。
public void exportExcel1(HttpServletResponse response) throws IOException {
setExportHeader(response);
//查出所有数据
List < Salaries > salaries = salariesMapper.selectList(null);
EasyExcel.write(response.getOutputStream(), Salaries.class)
.sheet() //写到一个sheet
.doWrite(salaries);
}方案二
- 查全表:一次性查询出整个表的数据。
- 写入多个sheet:根据行数限制,将数据分批写入多个 sheet 中。
优点:解决了单个 sheet 的行数限制问题。
缺点:
- 一次性查询大量数据仍然会占用大量内存。
- 需要在逻辑上处理如何分配数据到不同的 sheet 中,大大增加了实现的复杂度。
public void exportExcel2(HttpServletResponse response) throws IOException {
setExportHeader(response);
//查出所有数据
List < Salaries > salaries = salariesMapper.selectList(null);
try (ExcelWriter excelWriter = EasyExcel.write(response.getOutputStream(), Salaries.class).build()) {
//创建3个sheet
WriteSheet writeSheet1 = EasyExcel.writerSheet(1, "模板1").build();
WriteSheet writeSheet2 = EasyExcel.writerSheet(2, "模板2").build();
WriteSheet writeSheet3 = EasyExcel.writerSheet(3, "模板3").build();
//将查出的数据进行分割
List < Salaries > data1 = salaries.subList(0, salaries.size() / 3);
List < Salaries > data2 = salaries.subList(salaries.size() / 3, salaries.size() * 2 / 3);
List < Salaries > data3 = salaries.subList(salaries.size() * 2 / 3, salaries.size());
//写入3个sheet
excelWriter.write(data1, writeSheet1);
excelWriter.write(data2, writeSheet2);
excelWriter.write(data3, writeSheet3);
}
}方案三(推荐)
解释:
- 分页查询:将数据分页查询,每次查询一页数据。
- 每页数据写入每个sheet:每页数据写入不同的 sheet。
优点:
- 内存占用更均衡,不会一次性查询大量数据。
- 适用于大数据量,可以逐页处理,不会超过单个 sheet 的行数限制。
缺点:
- 实现稍复杂,需要处理分页逻辑和 sheet 切换。
- 写入多个 sheet 可能会增加文件大小和处理时间。
public void exportExcel3(HttpServletResponse response) throws IOException {
setExportHeader(response);
try (ExcelWriter excelWriter = EasyExcel.write(response.getOutputStream(), Salaries.class).build()) {
//查询表数据条数
Long count = salariesMapper.selectCount(null);
Integer pages = 10; //定义分成10页数据
Long size = count / pages; //每页条数
for (int i = 0; i < pages; i++) {
//pages 页条数据,就创建pages页个 sheet
WriteSheet writeSheet = EasyExcel.writerSheet(i, "模板" + i).build();
Page < Salaries > page = new Page < > ();
page.setCurrent(i + 1);
page.setSize(size);
Page < Salaries > selectPage = salariesMapper.selectPage(page, null);
excelWriter.write(selectPage.getRecords(), writeSheet);
}
}
}方案四(推荐)
- 多线程分页查询:使用多线程并行进行分页查询,每个线程处理一部分数据。
- 每页数据写入每个sheet:每个线程处理的数据写入不同的 sheet。
优点:
- 并行处理,极大提高查询速度。
- 内存使用更加高效,因为每个线程只处理自己的一部分数据。
- 有助于充分利用多核 CPU 的能力。
缺点:
- 需要合理管理线程池,避免资源竞争导致性能瓶颈。
- 可能引入并发访问数据库的问题,需要小心处理数据库连接和事务。
额外说一点:easyexcel 是不支持并发写入多个sheet,只能一个sheet一个sheet的写。因此尽管是多线程分页查询了,也只能单线程写入同一个excel
public void exportExcel4(HttpServletResponse response) throws IOException, InterruptedException {
setExportHeader(response);
//查询表数据条数
Long count = salariesMapper.selectCount(null);
Integer pages = 20; //定义分成10页数据
Long size = count / pages; //每页条数
//创建pages个线程
ExecutorService executorService = Executors.newFixedThreadPool(pages);
CountDownLatch countDownLatch = new CountDownLatch(pages);
Map < Integer, Page < Salaries >> pageMap = new HashMap < > ();
for (int i = 0; i < pages; i++) {
int finalI = i;
executorService.submit(new Runnable() {@
Override
public void run() {
//多线程分页查询
Page < Salaries > page = new Page < > ();
page.setCurrent(finalI + 1);
page.setSize(size);
Page < Salaries > selectPage = salariesMapper.selectPage(page, null);
pageMap.put(finalI, selectPage);
countDownLatch.countDown();
}
});
}
countDownLatch.await();
try (ExcelWriter excelWriter = EasyExcel.write(response.getOutputStream(), Salaries.class).build()) {
//easyexcel不支持并发写入多个sheet,只能一个sheet一个sheet的写
for (Map.Entry < Integer, Page < Salaries >> entry: pageMap.entrySet()) {
Integer num = entry.getKey();
Page < Salaries > salariesPage = entry.getValue();
WriteSheet writeSheet = EasyExcel.writerSheet(num, "模板" + num).build();
//写入多个sheet
excelWriter.write(salariesPage.getRecords(), writeSheet);
}
}
// https://github.com/alibaba/easyexcel/issues/1040
}方案选择
对于百万级数据的导出,建议选择方案 3 或方案 4:
- 方案 3(分页查询,每页数据写入每个sheet):这个方案在实现上适中,能够有效解决单个 sheet 的行数限制问题,并且在内存使用上较为均衡。虽然实现稍复杂,但性能和资源利用率较好,适合大多数场景。
- 方案 4(多线程分页查询;每页数据写入每个sheet):这个方案适用于需要极高性能和速度的场景。通过多线程并行处理,可以极大提高导出效率,但实现复杂度较高,需要处理好线程同步和资源共享问题。如果系统资源(如 CPU 和内存)充足,并且能够合理管理多线程,这是性能最优的选择。
综上所述,方案 3 是一个兼顾实现复杂度和性能的选择,而方案 4 可以在资源充足(同样是全表放入内存中)且需要高性能的情况下使用。根据具体需求和系统资源,选择最合适的方案。
注意点
需要注意的是,分布式环境下,可能存在的问题:
- 同一个接口同时导入数据 的并发问题
- 正在导入数据时,不能在此时执行导出操作
以上问题可以通过 分布式锁来实现
模板方法设计模式简化EasyExcel的读取
看 官方文档 上读取Excel挺简单的,只需要一行代码
/**
* 指定列的下标或者列名
*
* <p>1. 创建excel对应的实体对象,并使用{@link ExcelProperty}注解. 参照{@link IndexOrNameData}
* <p>2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link IndexOrNameDataListener}
* <p>3. 直接读即可
*/
@Test
public void indexOrNameRead() {
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里默认读取第一个sheet
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}EasyExcel.read 整体流程图如下:

但仔细看,其实这里还需要创建一个回调监听器 DemoDataListener,也就是针对每个DemoData 即每个Excel 都需要创建一个单独的回调监听器类。
// 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
@Slf4j
public class DemoDataListener implements ReadListener<DemoData> {
/**
* 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 100;
/**
* 缓存的数据
*/
private List<DemoData> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
/**
* 假设这个是一个DAO,当然有业务逻辑这个也可以是一个service。当然如果不用存储这个对象没用。
*/
private DemoDataDAO demoDAO;
public DemoDataListener() {
// 这里是demo,所以随便new一个。实际使用如果到了spring,请使用下面的有参构造函数
demoDAO = new DemoDAO();
}
/**
* 如果使用了spring,请使用这个构造方法。每次创建Listener的时候需要把spring管理的类传进来
*
* @param demoDAO
*/
public DemoDataListener(DemoDataDAO demoDAO) {
this.demoDAO = demoDAO;
}
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(DemoData data, AnalysisContext context) {
log.info("解析到一条数据:{}", JSON.toJSONString(data));
cachedDataList.add(data);
// 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 这里也要保存数据,确保最后遗留的数据也存储到数据库
saveData();
log.info("所有数据解析完成!");
}
/**
* 加上存储数据库
*/
private void saveData() {
log.info("{}条数据,开始存储数据库!", cachedDataList.size());
demoDAO.save(cachedDataList);
log.info("存储数据库成功!");
}
}在使用EasyExcel读取Excel时就在想能够如何简化读取方式,而不是读取每个Excel都创建一个XXDataListener 的监听器类
首先,可以把DataListener加上泛型,共用一个DataListener<T>
看上面代码,只需要在new的时候再去new DataListener<DemoData>即可
但是,如果要传递Dao 和 并且每个Dao如何保存数据,而且保存数据前可能还需要对数据进行校验,也就存在以下问题:
- 如何校验表头?
- 如何处理表头数据?
- 如何校验真实数据?
- 如何处理真实数据?
那么该如何处理呢?
最后想到了可以用Function(数据校验) + Consumer(数据存储) + 模板方法设计模式,创建一个共用的EasyExcel读取监听器,从而不在监听器中对数据进行处理,把处理都前置。
EasyExcel 的监听器类 Listener 已经定义了每一步会做什么,如通过 invokeHead 方法一行一行读取表头数据,通过invoke 方法一行一行读取真实数据。
也就是说,我们已经知道了 Listener 类所需的关键步骤,即一行一行读取数据,而且确定了这些步骤的执行顺序,但表头数据的校验和处理,真实数据的校验和处理还无法确定;并且这些是由导入的具体数据决定的,不同的表会有不同的校验 和 处理方式。基于此,我们就可以想到用 模板方法模式!
代码详情如下:
import cn.hutool.core.util.StrUtil;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.metadata.data.ReadCellData;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.excel.util.ConverterUtils;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.function.Consumer;
import java.util.function.Function;
@Slf4j
public class EasyExcelListener<T> implements ReadListener<T> {
private static final int defaultBatchSize = 5000;
private final int batchSize;
private List<Map<Integer, String>> headData;
private List<T> realData;
private final int headRowCount;
private Function<Map<Integer, String>, String> headDataCheck;
private final Consumer<List<Map<Integer, String>>> headDataConsumer;
private Function<T, String> realDataCheck;
private final Consumer<List<T>> realDataConsumer;
private final List<String> errorList;
/**
* 构造函数
*
* @param headRowCount 表头行数
* @param headDataCheck 表头数据校验
* @param headDataConsumer 表头数据处理
* @param realDataCheck 真实数据校验
* @param realDataConsumer 真实数据处理
*/
public EasyExcelListener(int headRowCount, Function<Map<Integer, String>, String> headDataCheck, Consumer<List<Map<Integer, String>>> headDataConsumer
, Function<T, String> realDataCheck, Consumer<List<T>> realDataConsumer) {
this.headRowCount = headRowCount;
this.batchSize = defaultBatchSize;
this.headDataCheck = headDataCheck;
this.headDataConsumer = headDataConsumer;
this.realDataCheck = realDataCheck;
this.realDataConsumer = realDataConsumer;
headData = new ArrayList<>(headRowCount);
realData = new ArrayList<>(batchSize);
errorList = new ArrayList<>();
}
public EasyExcelListener(int headRowCount, int batchSize, Function<Map<Integer, String>, String> headDataCheck, Consumer<List<Map<Integer, String>>> headDataConsumer
, Function<T, String> realDataCheck, Consumer<List<T>> realDataConsumer) {
this.headRowCount = headRowCount;
this.batchSize = batchSize;
this.headDataCheck = headDataCheck;
this.headDataConsumer = headDataConsumer;
this.realDataCheck = realDataCheck;
this.realDataConsumer = realDataConsumer;
headData = new ArrayList<>(headRowCount);
realData = new ArrayList<>(batchSize);
errorList = new ArrayList<>();
}
@Override
public void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) {
//获取表头数据
Map<Integer, String> map = ConverterUtils.convertToStringMap(headMap, context);
//校验表头数据
String checkRes = headDataCheck.apply(map);
if (StrUtil.isNotBlank(checkRes)) {
int rowIndex = context.readRowHolder().getRowIndex() + 1;
errorList.add("行号为:" + rowIndex + checkRes);
return;
}
if (!errorList.isEmpty()) {
//有错误信息,就不会再处理,只做校验
return;
}
//没有问题的数据添加进list中
headData.add(map);
if (context.readRowHolder().getRowIndex() == headRowCount - 1) {
//全部读取完表头数据后,处理表头数据
headDataConsumer.accept(headData);
}
}
@Override
public void invoke(T data, AnalysisContext context) {
//判断真实数据是否符合要求
String checkRes = realDataCheck.apply(data);
if (StrUtil.isNotBlank(checkRes)) {
int rowIndex = context.readRowHolder().getRowIndex() + 1;
errorList.add("行号为:" + rowIndex + checkRes);
return;
}
//没有报错的数据添加进list
realData.add(data);
if (realData.size() >= batchSize) {
//处理真实数据
realDataConsumer.accept(realData);
//清空realData
realData = new ArrayList<>(batchSize);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 解析完所有excel行, 剩余的数据还需要进行处理
realDataConsumer.accept(realData);
}
public List<Map<Integer, String>> getHeadData() {
return headData;
}
public List<T> getRealData() {
return realData;
}
public List<String> getErrorList() {
return errorList;
}
}EasyExcel读取封装后的使用示例:
//构建 EasyExcelListener
EasyExcelListener < TaskImportDTO > taskImportDTOEasyExcelListener =
new EasyExcelListener < > (
4, //表头行数
(map) - > { //表头数据校验
return checkMap(map, startTime, taskMainDOList);
}, headList - > {
//表头数据处理
saveHeadData(headList);
}, (data) - > {
//真实数据校验
return checkImportData(data);
}, realDataList - > {
//真实数据处理
saveRealData(realDataList);
}
);
//读取数据
EasyExcelUtil.read(inputStream, TaskImportDTO.class, taskImportDTOEasyExcelListener)
.headRowNumber(4) //表头行数
.sheet()
.doRead();上面的 checkMap ,saveHeadData,checkImportData,saveRealData皆为针对本次导入数据自定义的校验和处理方法。
若还有其它导入需求,只需new EasyExcelListener 方法,并自定义自己的校验和处理逻辑即可,从而完成代码复用!
替代产品
有个好消息就是,EasyExcel的作者创建了新项目:FastExcel。
开源地址:https://github.com/CodePhiliaX/fastexcel
作者选择为它起名为 FastExcel,以突出这个框架在处理 Excel 文件时的高性能表现,而不仅仅是简单易用。
FastExcel 将始终坚持免费开源,并采用最开放的 MIT 协议,使其适用于任何商业化场景。这为开发者和企业提供了极大的自由度和灵活性。FastExcel 的一些显著特点包括:
- 完全兼容原 EasyExcel 的所有功能和特性,这使得用户可以无缝过渡。
- 从 EasyExcel 迁移到 FastExcel 只需简单地更换包名和 Maven 依赖即可完成升级。
- 在功能上,比 EasyExcel 提供更多创新和改进。
- FastExcel 1.0.0 版本新增了读取 Excel 指定行数和将 Excel 转换为 PDF 的功能。
他们计划在未来推出更多新特性,以不断提升用户体验和工具实用性。FastExcel 致力于成为处理 Excel 文件的最佳选择。
主要特性:
- 高性能读写: FastExcel 专注于性能优化,能够高效处理大规模的 Excel 数据。相比一些传统的 Excel 处理库,它能显著降低内存占用。
- 简单易用: 该库提供了简洁直观的 API,使得开发者可以轻松集成到项目中,无论是简单的 Excel 操作还是复杂的数据处理都能快速上手。
- 流式操作: FastExcel 支持流式读取,将一次性加载大量数据的问题降到最低。这种设计方式在处理数十万甚至上百万行的数据时尤为重要。
当前 FastExcel 底层使用 poi 作为基础包,如果项目中已经有 poi 相关组件,需要手动排除 poi 的相关 jar 包。
如果使用 Maven 进行项目构建,请在 pom.xml 文件中引入以下配置:
<dependency>
<groupId>cn.idev.excel</groupId>
<artifactId>fastexcel</artifactId>
<version>1.0.0</version>
</dependency>EasyExcel 与 FastExcel 的区别:
- FastExcel 支持所有 EasyExcel 的功能,但是 FastExcel 的性能更好,更稳定。
- FastExcel 与 EasyExcel 的 API 完全一致,可以无缝切换。
- FastExcel 会持续的更新,修复 bug,优化性能,增加新功能。EasyExcel 如何升级到 FastExcel
修改依赖
将 EasyExcel 的依赖替换为 FastExcel 的依赖,如下:
<!-- easyexcel 依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>xxxx</version>
</dependency>依赖替换为
<dependency>
<groupId>cn.idev.excel</groupId>
<artifactId>fastexcel</artifactId>
<version>1.0.0</version>
</dependency>修改代码
将 EasyExcel 的包名替换为 FastExcel 的包名,如下:
import com.alibaba.excel.**;替换为
import cn.idev.excel.**;不修改代码直接依赖 FastExcel
如果由于种种原因不想修改代码,可以直接依赖 FastExcel ,然后在 pom.xml 文件中直接依赖 FastExcel。EasyExcel 与 FastExcel 可以共存,但是长期建议替换为 FastExcel。
建议以后使用 FastExcel 类
为了兼容性考虑保留了 EasyExcel 类,但是建议以后使用 FastExcel 类,FastExcel 类是FastExcel 的入口类,功能包含了 EasyExcel 类的所有功能,以后新特性仅在 FastExcel 类中添加。
简单示例:读取 Excel 文件 下面是读取 Excel 文档的例子:
// 实现 ReadListener 接口,设置读取数据的操作
public class DemoDataListener implements ReadListener<DemoData> {
@Override
public void invoke(DemoData data, AnalysisContext context) {
System.out.println("解析到一条数据" + JSON.toJSONString(data));
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
System.out.println("所有数据解析完成!");
}
}
public static void main(String[] args) {
String fileName = "demo.xlsx";
// 读取 Excel 文件
FastExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}简单示例:创建 Excel 文件 下面是一个创建 Excel 文档的简单例子:
// 示例数据类
public class DemoData {
@ExcelProperty("字符串标题")
private String string;
@ExcelProperty("日期标题")
private Date date;
@ExcelProperty("数字标题")
private Double doubleData;
@ExcelIgnore
private String ignore;
}
// 填充要写入的数据
private static List<DemoData> data() {
List<DemoData> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
DemoData data = new DemoData();
data.setString("字符串" + i);
data.setDate(new Date());
data.setDoubleData(0.56);
list.add(data);
}
return list;
}
public static void main(String[] args) {
String fileName = "demo.xlsx";
// 创建一个名为“模板”的 sheet 页,并写入数据
FastExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}