大部分互联网公司都需要处理计数器场景,例如风控系统的请求频控、内容平台的播放量统计、电商系统的库存扣减等。
传统方案一般会直接使用RedisUtil.incr(key),这是最简单的方式,但这种方式在生产环境中会暴露严重问题:
// 隐患示例
public long addOne(String key) {
Long result = RedisUtil.incr(key);
// 若未设置TTL,key将永久驻留内存
return result;
}大部分互联网公司都需要处理计数器场景,例如风控系统的请求频控、内容平台的播放量统计、电商系统的库存扣减等。
传统方案一般会直接使用RedisUtil.incr(key),这是最简单的方式,但这种方式在生产环境中会暴露严重问题:
// 隐患示例
public long addOne(String key) {
Long result = RedisUtil.incr(key);
// 若未设置TTL,key将永久驻留内存
return result;
}Redis是一个高效的内存数据库,它支持包括String、List、Set、SortedSet和Hash等数据类型的存储,在Redis中通常根据数据的key查询其value值,Redis没有模糊条件查询,在面对一些需要分页、排序以及条件查询的场景时(如评论,时间线,检索等),只凭借Redis所提供的功能就不太好不处理了。
本文不对Redis的特性做过多赘述。由于之前基于业务问题需要实现基于Redis的条件查询和分页功能,在百度上查询了不少文章,基本不是只有分页功能就是只有条件查询功能的实现,缺少两者组合的解决方案。因此,本文将基于Redis提供条件查询+分页的技术解决方案。
今天来讲讲 Redis 的请求监听,通俗点说,就是Redis是如何监听客户端发出的set、get等命令的。
众所周知,Redis 是单进程单线程架构,虽然是单进程单线程,但是Redis的性能却毫不逊色,能轻松应对一般的高并发场景,那么Redis究竟是施了什么魔法呢?
其实 Redis 的原理和 Nginx 差不多,都利用了 IO 多路复用来提高处理能力,所谓多路复用,就是一个线程可以同时处理多个IO操作,当 某个 IO 操作 Ready 时,操作系统会主动通知进程。使用 IO 多路复用,我们可以使用 epoll、kqueue、select,API 都差不多。
一般来说,现在的redis连接都会有池化技术, Redis连接池技术有以下好处:
资源复用:连接池允许多个客户端共享一定数量的数据库连接。当一个客户端完成操作并释放连接时,这个连接可以被另一个客户端重用,而不是关闭后重新建立,这大大减少了创建和销毁连接所需的时间和资源。
减少等待时间:预创建的连接可以立即提供给需要它们的客户端。这意味着应用程序不需要等待建立连接就可以执行操作,从而提高了响应速度。
提高性能:连接池可以减少因频繁打开和关闭连接造成的开销,因为建立数据库连接通常是一个高成本的操作,包括网络延迟、认证等过程。
连接数控制:连接池可以限制系统中活跃的总连接数。这防止了系统打开过多的连接,从而避免了对数据库服务器资源的过度消耗和可能的拒绝服务。
自动管理:连接池通常提供自动化的连接管理功能,如检测空闲连接、移除无效连接等,而不需要开发者手动干预。
减轻数据库压力:通过重用连接,连接池使得数据库服务器不必处理大量短生命周期的连接,这有助于维持数据库的稳定性和性能。
配置灵活性:可以根据应用程序的负载特征和数据库服务器的能力对连接池进行配置,如调整池的大小、连接的生命周期等。
故障恢复:当某个连接发生故障时,连接池可以提供一个新的连接替代它,从而增强了应用程序的鲁棒性。
更好的并发处理:在高并发环境下,连接池可以更有效地管理不同线程或进程的连接需求,减少了锁的竞争和上下文切换的成本。
简化编程模型:开发者可以从连接池中获取连接,执行操作,然后返回连接,而无需关心连接的创建和关闭,简化了编程模型。
来源:稀土掘金社区深入理解缓存原理与实战设计,Seven进行了部分补充完善
通过前面的文章,我们一起剖析了Guava Cache、Caffeine、Ehcache等本地缓存框架的原理与使用场景,也一同领略了以Redis为代表的集中式缓存在分布式高并发场景下无可替代的价值。
用户的数据一般都是存储于数据库,数据库的数据是落在磁盘上的,磁盘的读写速度可以说是计算机里最慢的硬件了。
当用户的请求,都访问数据库的话,请求数量一上来,数据库很容易就奔溃的了,所以为了避免用户直接访问数据库,会用 Redis 作为缓存层。因为 Redis 是内存数据库,我们可以将数据库的数据缓存在 Redis 里,相当于数据缓存在内存,内存的读写速度比硬盘快好几个数量级,这样大大提高了系统性能。
当使用缓存时,通常有两个目标:第一,提升响应效率和并发量;第二,减轻数据库的压力。
而引入了缓存层,就会有缓存异常的三个问题,分别是缓存雪崩、缓存击穿、缓存穿透。这三个问题的发生,都是因为在某些特殊情况下,缓存失去了预期的功能所致。
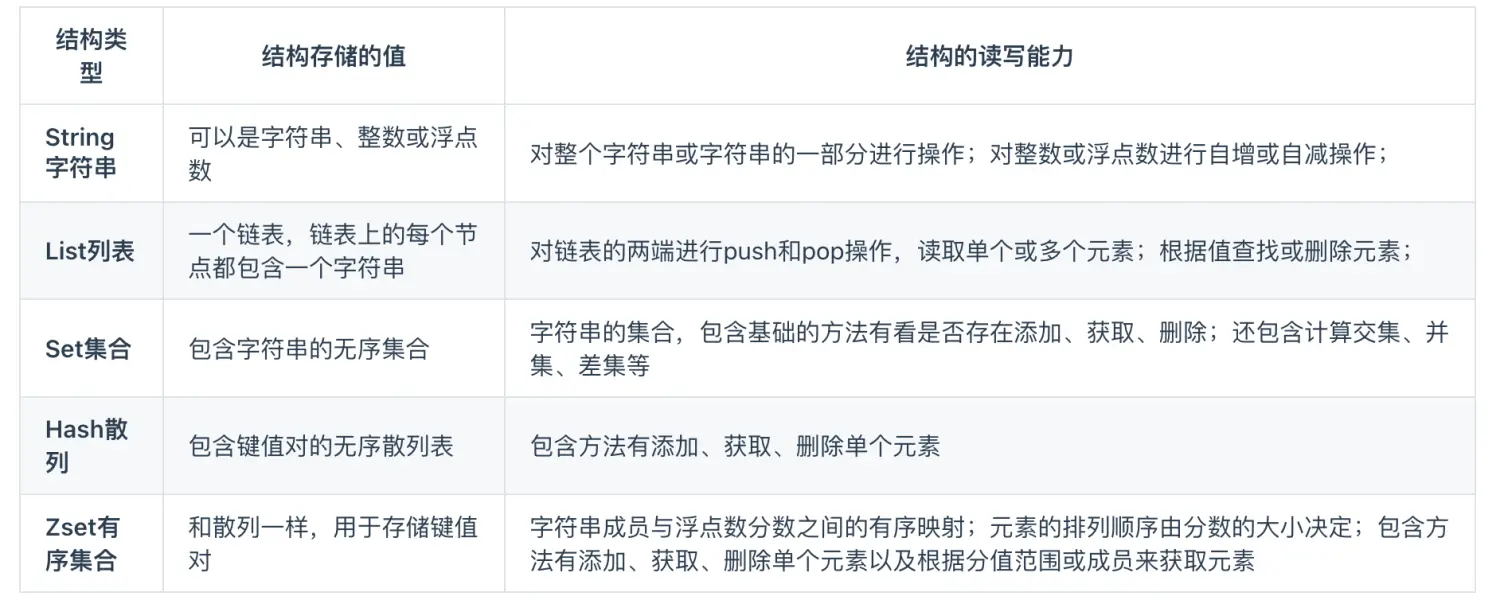
计算Redis容量,并不只是仅仅计算key占多少字节,value占多少字节,因为Redis为了维护自身的数据结构,也会占用部分内存,本文章简单介绍每种数据类型(String、Hash、Set、ZSet、List)占用内存量,供做Redis容量评估时使用。
在看这里之前,可以先看一下底层 - 数据结构 这篇文章
Redis Cluster 的 GUI 工具;
Redis中的数据类型指的是 value存储的数据类型,key都是以String类型存储的,value根据场景需要,可以以String、List等类型进行存储。
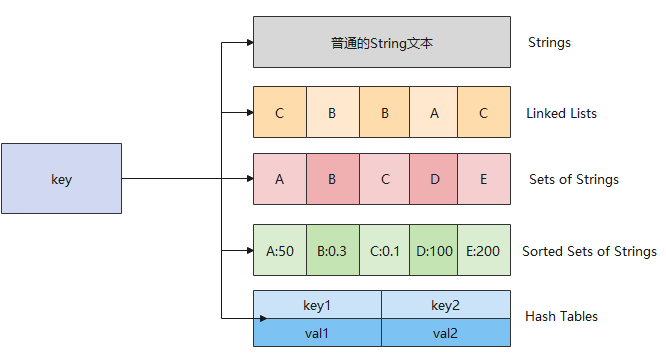
各数据类型介绍: