概述
树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
树的定义:树是⼀种数据结构,它是由n(n≥1)个有限节点组成⼀个具有层次关系的集合。把它叫做“树”是因为它看起来像⼀棵倒挂的树,也就是说它是根朝上,⽽叶朝下的。
一棵树具有以下特点:
- 每个节点有零个或多个⼦节点
- 没有⽗节点的节点称为根节点
- 每⼀个⾮根节点有且只有⼀个⽗节点
- 除了根节点外,每个⼦节点可以分为多个不相交的⼦树
- 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
- 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
- 一棵树不包含回路。
下图就是一颗树,并且是一颗二叉树。

如上图所示,通过上面这张图说明一下树中的常用概念:
- 节点:树中的每个元素都可以统称为节点。
- 节点的度:⼀个节点含有的⼦树的个数称为该节点的度
- 树的度:⼀棵树中,最⼤的节点度称为树的度;
- 叶节点或终端节点:度为零的节点;
- ⾮终端节点或分⽀节点:度不为零的节点;
- 根节点:顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
- 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
- 子节点:一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
- 兄弟节点:具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
- 叶子节点:没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
- 节点的高度:该节点到叶子节点的最长路径所包含的边数。
- 节点的深度:根节点到该节点的路径所包含的边数
- 节点的层数:节点的深度+1。
- 树的高度:根节点的高度。
关于树的深度和高度的定义可以看 stackoverflow 上的这个问题:What is the difference between tree depth and height? 。
二叉树的存储
二叉树的存储主要分为 链式存储 和 顺序存储 两种:
链式存储
和链表类似,二叉树的链式存储依靠指针将各个节点串联起来,不需要连续的存储空间。
每个节点包括三个属性:
- 数据 data。data 不一定是单一的数据,根据不同情况,可以是多个具有不同类型的数据。
- 左节点指针 left
- 右节点指针 right。
可是 JAVA 没有指针啊!
那就直接引用对象呗(别问我对象哪里找)

顺序存储
顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2i 的位置,它的右子节点存储在下标为 2i+1 的位置。
一棵完全二叉树的数组顺序存储如下图所示:
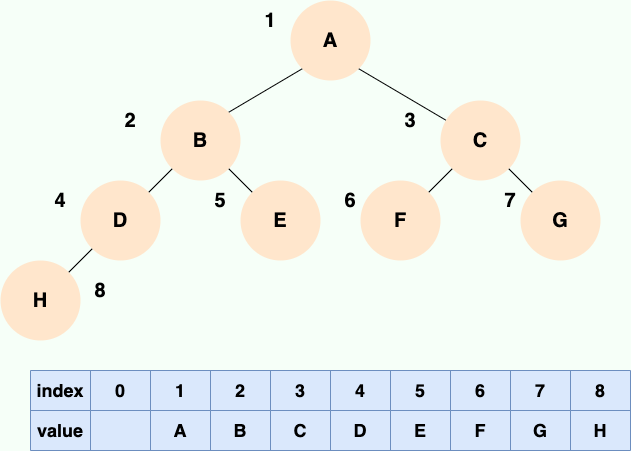
大家可以试着填写一下存储如下二叉树的数组,比较一下和完全二叉树的顺序存储有何区别:

可以看到,如果我们要存储的二叉树不是完全二叉树,在数组中就会出现空隙,导致内存利用率降低
二叉树的遍历
递归遍历
先序遍历

二叉树的先序遍历,就是先输出根结点,再遍历左子树,最后遍历右子树,遍历左子树和右子树的时候,同样遵循先序遍历的规则,也就是说,我们可以递归实现先序遍历。
代码如下:
public void preOrder(TreeNode root){
if(root == null){
return;
}
system.out.println(root.data);
preOrder(root.left);
preOrder(root.right);
}中序遍历

二叉树的中序遍历,就是先递归中序遍历左子树,再输出根结点的值,再递归中序遍历右子树,大家可以想象成一巴掌把树压扁,父结点被拍到了左子节点和右子节点的中间,如下图所示:

代码如下:
public void inOrder(TreeNode root){
if(root == null){
return;
}
inOrder(root.left);
system.out.println(root.data);
inOrder(root.right);
}后序遍历

二叉树的后序遍历,就是先递归后序遍历左子树,再递归后序遍历右子树,最后输出根结点的值
代码如下:
public void postOrder(TreeNode root){
if(root == null){
return;
}
postOrder(root.left);
postOrder(root.right);
system.out.println(root.data);
}层序遍历
层序遍历属于迭代遍历,也比较简单

前序遍历
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
// 前序遍历顺序:中-左-右,入栈顺序:中-右-左
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.right != null){
stack.push(node.right);
}
if (node.left != null){
stack.push(node.left);
}
}
return result;
}中序遍历
刚刚在进行前序遍历迭代的过程中,其实有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点,所以刚刚能写出相对简洁的代码
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
// 中序遍历顺序: 左-中-右 入栈顺序: 左-右
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
cur = cur.left;
}else{
cur = stack.pop();
result.add(cur.val);
cur = cur.right;
}
}
return result;
}后序遍历
后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了
// 后序遍历顺序 左-右-中 入栈顺序:中-左-右 出栈顺序:中-右-左, 最后翻转结果
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.left != null){
stack.push(node.left);
}
if (node.right != null){
stack.push(node.right);
}
}
Collections.reverse(result);
return result;
}二叉树的分类
二叉树(Binary tree)是每个节点最多只有两个分支(即不存在分支度大于 2 的节点)的树结构。
二叉树 的分支通常被称作“左子树”或“右子树”。并且,二叉树 的分支具有左右次序,不能随意颠倒。
二叉树 的第 i 层至多拥有 2^(i-1) 个节点,深度为 k 的二叉树至多总共有 2^(k+1)-1 个节点(满二叉树的情况),至少有 2^(k) 个节点(关于节点的深度的定义国内争议比较多,我个人比较认可维基百科对节点深度的定义)。

⼆叉树在Java 中表示:
public class TreeLinkNode {
int val;
TreeLinkNode left = null;
TreeLinkNode right = null;
TreeLinkNode next = null;
TreeLinkNode(int val) {
this.val = val;
}
}满二叉树
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是 满二叉树。也就是说,如果一个二叉树的层数为 K,且结点总数是(2^k) -1 ,则它就是 满二叉树。如下图所示:

完全二叉树
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 完全二叉树 。
大家可以想象为一棵树从根结点开始扩展,扩展完左子节点才能开始扩展右子节点,每扩展完一层,才能继续扩展下一层。如下图所示:
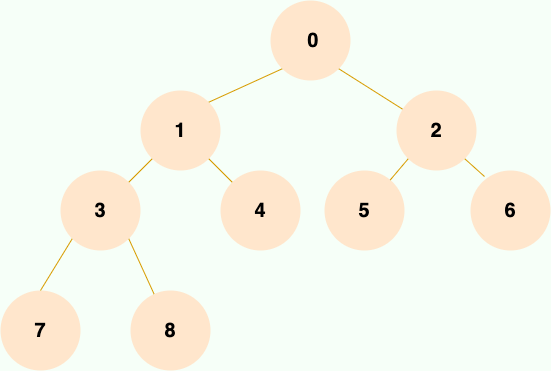
完全二叉树有一个很好的性质:父结点和子节点的序号有着对应关系。
细心的小伙伴可能发现了,当根节点的值为 1 的情况下,若父结点的序号是 i,那么左子节点的序号就是 2i,右子节点的序号是 2i+1。这个性质使得完全二叉树利用数组存储时可以极大地节省空间,以及利用序号找到某个节点的父结点和子节点,后续二叉树的存储会详细介绍。
若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
二叉搜索树
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
下面这两棵树都是搜索树

平衡二叉搜索树(AVL树)
平衡二叉树 是一棵二叉排序树,且具有以下性质:
- 可以是一棵空树
- 如果不是空树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树的常用实现方法有 红黑树、替罪羊树、加权平衡树、伸展树 等。
在给大家展示平衡二叉树之前,先给大家看一棵树:

你管这玩意儿叫树???
没错,这玩意儿还真叫树,只不过这棵树已经退化为一个链表了,我们管它叫 斜树。
如果这样,那我为啥不直接用链表呢?
谁说不是呢?
二叉树相比于链表,由于父子节点以及兄弟节点之间往往具有某种特殊的关系,这种关系使得我们在树中对数据进行搜索和修改时,相对于链表更加快捷便利。
但是,如果二叉树退化为一个链表了,那么那么树所具有的优秀性质就难以表现出来,效率也会大打折,为了避免这样的情况,我们希望每个做 “家长”(父结点) 的,都 一碗水端平,分给左儿子和分给右儿子的尽可能一样多,相差最多不超过一层,如下图所示:

基本操作
查找元素
- 时间复杂度:O(log n)
- 方法:与普通二叉搜索树相同
插入元素
- 时间复杂度:O(log n)
- 步骤:
- 执行标准二叉搜索树插入
- 更新受影响节点的高度
- 计算平衡因子
- 如失衡,执行旋转操作恢复平衡
删除元素
- 时间复杂度:O(log n)
- 步骤:
- 执行标准二叉搜索树删除
- 更新受影响节点的高度
- 计算平衡因子
- 如失衡,执行旋转操作恢复平衡
旋转操作
- 左旋(LL):针对右子树高于左子树过多
- 右旋(RR):针对左子树高于右子树过多
- 左右旋(LR):先对左子树进行左旋,再对节点进行右旋
- 右左旋(RL):先对右子树进行右旋,再对节点进行左旋
基础实现
/**
* AVL树的Java实现
*/
public class AVLTree {
// 树节点定义
class Node {
int key; // 节点值
Node left; // 左子节点
Node right; // 右子节点
int height; // 节点高度
Node(int key) {
this.key = key;
this.height = 1; // 新节点高度初始为1
}
}
Node root; // 根节点
// 获取节点高度,空节点高度为0
private int height(Node node) {
if (node == null) {
return 0;
}
return node.height;
}
// 获取节点的平衡因子
private int getBalanceFactor(Node node) {
if (node == null) {
return 0;
}
return height(node.left) - height(node.right);
}
// 更新节点高度
private void updateHeight(Node node) {
if (node == null) {
return;
}
node.height = Math.max(height(node.left), height(node.right)) + 1;
}
// 右旋转(处理左左情况)
private Node rotateRight(Node y) {
Node x = y.left;
Node T2 = x.right;
// 执行旋转
x.right = y;
y.left = T2;
// 更新高度
updateHeight(y);
updateHeight(x);
return x; // 返回新的根节点
}
// 左旋转(处理右右情况)
private Node rotateLeft(Node x) {
Node y = x.right;
Node T2 = y.left;
// 执行旋转
y.left = x;
x.right = T2;
// 更新高度
updateHeight(x);
updateHeight(y);
return y; // 返回新的根节点
}
// 插入节点
public void insert(int key) {
root = insertNode(root, key);
}
private Node insertNode(Node node, int key) {
// 1. 执行标准BST插入
if (node == null) {
return new Node(key);
}
if (key < node.key) {
node.left = insertNode(node.left, key);
} else if (key > node.key) {
node.right = insertNode(node.right, key);
} else {
// 相同键值不做处理,或根据需求更新节点
return node;
}
// 2. 更新节点高度
updateHeight(node);
// 3. 获取平衡因子
int balance = getBalanceFactor(node);
// 4. 如果节点失衡,进行旋转调整
// 左左情况 - 右旋
if (balance > 1 && getBalanceFactor(node.left) >= 0) {
return rotateRight(node);
}
// 右右情况 - 左旋
if (balance < -1 && getBalanceFactor(node.right) <= 0) {
return rotateLeft(node);
}
// 左右情况 - 左右双旋
if (balance > 1 && getBalanceFactor(node.left) < 0) {
node.left = rotateLeft(node.left);
return rotateRight(node);
}
// 右左情况 - 右左双旋
if (balance < -1 && getBalanceFactor(node.right) > 0) {
node.right = rotateRight(node.right);
return rotateLeft(node);
}
// 返回未变化的节点引用
return node;
}
// 查找最小值节点
private Node findMinNode(Node node) {
Node current = node;
while (current.left != null) {
current = current.left;
}
return current;
}
// 删除节点
public void delete(int key) {
root = deleteNode(root, key);
}
private Node deleteNode(Node root, int key) {
// 1. 执行标准BST删除
if (root == null) {
return root;
}
if (key < root.key) {
root.left = deleteNode(root.left, key);
} else if (key > root.key) {
root.right = deleteNode(root.right, key);
} else {
// 找到要删除的节点
// 情况1:叶子节点或只有一个子节点
if (root.left == null || root.right == null) {
Node temp = (root.left != null) ? root.left : root.right;
// 没有子节点
if (temp == null) {
root = null;
} else {
// 一个子节点
root = temp;
}
} else {
// 情况2:有两个子节点
// 找到右子树的最小节点(中序后继)
Node temp = findMinNode(root.right);
// 复制中序后继的值到当前节点
root.key = temp.key;
// 删除中序后继
root.right = deleteNode(root.right, temp.key);
}
}
// 如果树只有一个节点,删除后直接返回
if (root == null) {
return root;
}
// 2. 更新高度
updateHeight(root);
// 3. 获取平衡因子
int balance = getBalanceFactor(root);
// 4. 进行旋转操作保持平衡
// 左左情况
if (balance > 1 && getBalanceFactor(root.left) >= 0) {
return rotateRight(root);
}
// 左右情况
if (balance > 1 && getBalanceFactor(root.left) < 0) {
root.left = rotateLeft(root.left);
return rotateRight(root);
}
// 右右情况
if (balance < -1 && getBalanceFactor(root.right) <= 0) {
return rotateLeft(root);
}
// 右左情况
if (balance < -1 && getBalanceFactor(root.right) > 0) {
root.right = rotateRight(root.right);
return rotateLeft(root);
}
return root;
}
// 查找节点
public boolean search(int key) {
return searchNode(root, key);
}
private boolean searchNode(Node root, int key) {
if (root == null) {
return false;
}
if (key == root.key) {
return true;
}
if (key < root.key) {
return searchNode(root.left, key);
} else {
return searchNode(root.right, key);
}
}
}优点
- 查找效率高:保证O(log n)的查找、插入和删除操作时间复杂度
- 自平衡:自动调整树的结构,防止最坏情况出现
- 稳定性:所有操作都有稳定的性能表现
- 可预测性:树高被严格限制,便于分析性能
缺点
- 实现复杂:相比普通二叉搜索树,实现复杂度高
- 额外空间:每个节点需要存储高度信息
- 旋转开销:插入删除过程中的旋转操作增加了额外计算开销
- 频繁平衡调整:对于高频插入删除的场景,频繁的平衡调整可能影响性能
应用场景
AVL树是最早被发明的自平衡二叉搜索树之一,适用于许多需要高效查找和维持数据有序性的场景。
比如内存管理器经常使用AVL树跟踪内存块的分配与释放。
在需要频繁执行范围查询的应用中,AVL树也比较适用,常用于实现区间查询功能。
相关的 LeetCode 热门题目
- 98. 验证二叉搜索树 - 要求验证一个给定的二叉树是否是有效的二叉搜索树。
- 700. 二叉搜索树中的搜索 - 在二叉搜索树中查找指定值的节点。
- 701. 二叉搜索树中的插入操作 - 在不破坏二叉搜索树性质的前提下插入新节点。
- 450. 删除二叉搜索树中的节点 - 实现二叉搜索树的删除操作。
扩展:其它树形结构
二叉堆
二叉堆是一种特殊的完全二叉树,常用于实现优先队列。最小堆的每个节点的值都小于或等于其子节点的值,最大堆的每个节点的值都大于或等于其子节点的值。二叉堆支持高效的插入、删除最值和构建操作。
二叉堆是一种特殊的完全二叉树数据结构,它满足堆属性。完全二叉树是指除了最后一层外,其他层的节点都是满的,而最后一层的节点都靠左排列。二叉堆主要有两种类型:
- 最大堆:每个父节点的值都大于或等于其子节点的值
- 最小堆:每个父节点的值都小于或等于其子节点的值
二叉堆的这种特殊结构使得它可以高效地找到最大值或最小值,所以也常被用来实现优先队列。
二叉堆的核心特性如下:
- 完全二叉树结构:除最底层外,每层都填满,且最底层从左到右填充
- 堆序性质:
- 最大堆:父节点值 ≥ 子节点值
- 最小堆:父节点值 ≤ 子节点值
- 高效的顶部元素访问:可以在O(1)时间内获取最大/最小元素
- 数组表示:虽然概念上是树结构,但通常用数组实现,这样可以节省指针开销并提高内存局部性
基本操作
插入元素(Insert)
- 首先将新元素添加到堆的末尾
- 然后通过"上浮"操作调整堆,直到满足堆性质
删除顶部元素(Extract-Max/Min):移除并返回堆顶元素(最大/最小值)
- 取出堆顶元素
- 将堆的最后一个元素移到堆顶
- 通过"下沉"操作调整堆,直到满足堆性质
上浮(Heapify-Up):将一个元素向上移动到合适位置的过程
- 比较当前元素与其父节点
- 如果不满足堆性质,则交换它们
- 重复此过程直到满足堆性质
下沉(Heapify-Down):将一个元素向下移动到合适位置的过程
- 比较当前元素与其最大(或最小)的子节点
- 如果不满足堆性质,则交换它们
- 重复此过程直到满足堆性质
基础实现
public class MinHeap {
private int[] heap;
private int size;
private int capacity;
// 构造函数
public MinHeap(int capacity) {
this.capacity = capacity;
this.size = 0;
this.heap = new int[capacity];
}
// 获取父节点索引
private int parent(int i) {
return (i - 1) / 2;
}
// 获取左子节点索引
private int leftChild(int i) {
return 2 * i + 1;
}
// 获取右子节点索引
private int rightChild(int i) {
return 2 * i + 2;
}
// 交换两个节点
private void swap(int i, int j) {
int temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
// 插入元素
public void insert(int key) {
if (size == capacity) {
System.out.println("堆已满,无法插入");
return;
}
// 先将新元素插入到堆的末尾
heap[size] = key;
int current = size;
size++;
// 上浮操作:将元素向上移动到合适位置
while (current > 0 && heap[current] < heap[parent(current)]) {
swap(current, parent(current));
current = parent(current);
}
}
// 获取最小元素(不删除)
public int peek() {
if (size <= 0) {
System.out.println("堆为空");
return -1;
}
return heap[0];
}
// 删除并返回最小元素
public int extractMin() {
if (size <= 0) {
System.out.println("堆为空");
return -1;
}
if (size == 1) {
size--;
return heap[0];
}
// 存储根节点(最小值)
int root = heap[0];
// 将最后一个元素放到根位置
heap[0] = heap[size - 1];
size--;
// 下沉操作:将根元素向下移动到合适位置
heapifyDown(0);
return root;
}
// 下沉操作
private void heapifyDown(int i) {
int smallest = i;
int left = leftChild(i);
int right = rightChild(i);
// 找出当前节点、左子节点和右子节点中的最小值
if (left < size && heap[left] < heap[smallest]) {
smallest = left;
}
if (right < size && heap[right] < heap[smallest]) {
smallest = right;
}
// 如果最小值不是当前节点,则交换并继续下沉
if (smallest != i) {
swap(i, smallest);
heapifyDown(smallest);
}
}
// 打印堆
public void printHeap() {
for (int i = 0; i < size; i++) {
System.out.print(heap[i] + " ");
}
System.out.println();
}
public static void main(String[] args) {
MinHeap minHeap = new MinHeap(10);
minHeap.insert(5);
minHeap.insert(3);
minHeap.insert(8);
minHeap.insert(1);
minHeap.insert(10);
System.out.println("构建的堆:");
minHeap.printHeap();
System.out.println("最小元素:" + minHeap.peek());
System.out.println("提取最小元素:" + minHeap.extractMin());
System.out.println("提取后的堆:");
minHeap.printHeap();
}
}优点
- 高效的优先级操作:O(1) 时间复杂度查找最大/最小元素
- 相对较快的插入和删除:O(log n) 时间复杂度
- 空间效率高:数组实现不需要额外的指针开销
- 实现简单:相比其他高级数据结构,二叉堆实现相对简单
- 内存局部性好:连续内存存储提高缓存命中率
缺点
- 有限的操作集:只支持查找最值,不支持高效的搜索、删除任意元素等操作
- 不支持快速合并:合并两个堆的操作较为复杂
- 不稳定性:相同优先级的元素,其相对顺序可能改变
- 对缓存不友好的访问模式:特别是在堆较大时,父子节点间的跳跃访问可能导致缓存未命中
应用场景
二叉堆广泛应用于各种算法和系统中:
- 优先队列实现:当需要频繁获取最大或最小元素时,二叉堆是最常用的数据结构。操作系统中的进程调度、网络路由算法都会使用优先队列来确定下一个处理的任务。
- 排序算法:堆排序利用二叉堆的特性,能够以O(n log n)的时间复杂度对数据进行排序,且空间复杂度为O(1),适合大数据排序。
- 图算法:许多图算法如Dijkstra最短路径、Prim最小生成树算法都使用优先队列来选择下一个处理的节点,二叉堆是其高效实现。
- 中位数和百分位数计算:通过维护两个堆(最大堆和最小堆),可以高效地跟踪数据流的中位数和其他统计值。
- 事件模拟:在离散事件模拟中,事件按时间顺序处理,优先队列可以确保按正确顺序处理事件。
- 数据流处理:在处理大量数据流时,如果只需要关注"最重要"的k个元素,可以维护一个大小为k的堆。
Java标准库中的堆实现
Java 提供了 PriorityQueue 类,它基于二叉堆实现:
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// 默认是最小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 添加元素
minHeap.add(5);
minHeap.add(3);
minHeap.add(8);
minHeap.add(1);
minHeap.add(10);
System.out.println("优先队列内容:" + minHeap);
System.out.println("最小元素:" + minHeap.peek());
System.out.println("提取最小元素:" + minHeap.poll());
System.out.println("提取后的优先队列:" + minHeap);
// 创建最大堆(通过自定义比较器)
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
maxHeap.add(5);
maxHeap.add(3);
maxHeap.add(8);
maxHeap.add(1);
maxHeap.add(10);
System.out.println("最大堆内容:" + maxHeap);
System.out.println("最大元素:" + maxHeap.peek());
}
}详情可以看:PriorityQueue
堆的变种
除了基本的二叉堆,还有几种重要的堆变种:
- d叉堆(d-ary Heap):每个节点最多有d个子节点,而不是2个。增加d值可以减少堆的高度,在某些应用中可以提高性能。
- 斐波那契堆(Fibonacci Heap):一种更复杂的堆结构,提供了更高效的合并操作和摊销时间复杂度。许多高级图算法使用斐波那契堆来提高性能。
- 左偏树(Leftist Heap):一种支持高效合并操作的堆,常用于并行计算和分布式系统。
- 配对堆(Pairing Heap):结构简单但性能优异的堆实现,特别适合需要频繁合并和减小键值的应用。
相关的 LeetCode 热门题目
- 23. 合并K个排序链表 - 使用最小堆来高效合并多个有序链表。
- 347. 前 K 个高频元素 - 使用堆来找出数组中出现频率最高的K个元素。
- 295. 数据流的中位数 - 使用一个最大堆和一个最小堆来跟踪数据流的中位数。
B树
B树是一种自平衡的多路搜索树,它是二叉搜索树的扩展,专为磁盘或其他外部存储设备设计。B树的每个节点拥有更多的子节点,这使树的高度更低,减少访问磁盘的次数。
B树中的几个关键概念:
- 阶(Order):定义了一个B树节点最多可以有多少个子节点。具有阶为m的B树也称为m阶B树。
- 内部节点(Internal Node):除根节点和叶节点外的所有节点。
- 叶节点(Leaf Node):没有子节点的节点。
- 键(Key):存储在节点中的值,用于指导搜索过程。
- 子节点(Child):节点的直接后代。
一个阶为m的B树满足以下性质:
- 每个节点最多有m个子节点
- 除了根节点和叶节点,每个节点至少有⌈m/2⌉个子节点
- 如果根节点不是叶节点,则至少有两个子节点
- 所有叶节点都在同一层
- 具有k个子节点的非叶节点包含k-1个键
B树核心特性:
- 自平衡性:B树通过分裂和合并操作保持平衡,确保所有操作的对数时间复杂度。
- 多路分支:每个节点可以有多个子节点,而不仅仅是二叉树的两个,这降低了树的高度。
- 有序特性:B树中的键是有序存储的,使得搜索、插入和删除操作高效。
- 适合外部存储:B树的设计是为了最小化磁盘访问次数,特别适合处理大量数据时。
- 分块存储:键和指针组织在块中,这种结构与磁盘页面或数据块的物理特性匹配。
基本操作
搜索操作:搜索B树中的键与搜索二叉搜索树类似,但需要在每个节点中遍历多个键
- 从根节点开始
- 在当前节点内部按顺序查找目标键
- 如果找到,返回结果
- 如果未找到且节点是叶节点,则键不存在
- 否则,根据键的大小选择合适的子树继续搜索
插入操作
- 找到合适的叶节点位置
- 将键插入到叶节点中
- 如果插入导致节点超出最大容量,则分裂节点:
- 选择中间键
- 将中间键上移到父节点
- 将原节点分为两个节点
- 如果父节点也超出容量,则继续向上分裂
删除操作
- 找到包含要删除键的节点
- 如果节点是叶节点,直接删除
- 如果节点是内部节点,用前驱或后继替换要删除的键
- 如果删除导致节点键数量少于最小要求:
- 尝试从兄弟节点借一个键
- 如果无法借用,则合并节点
优点
- 减少磁盘访问:B树的高度通常很低,即使存储大量数据也只需要少量磁盘访问。
- 适合大数据量:因为每个节点可以包含多个键,B树可以有效地存储和检索大量数据。
- 平衡性保证:B树始终保持平衡,没有最坏情况性能下降的问题。
- 高效的范围查询:由于键是有序的,B树支持高效的范围查询操作。
- 适合外部存储:B树的结构非常适合磁盘等外部存储系统,使其成为数据库索引的理想选择。
缺点
- 实现复杂:与二叉树相比,B树的实现更为复杂,特别是删除操作。
- 空间利用率:B树节点可能未被完全填充,导致一定程度的空间浪费。
- 不适合内存操作:对于完全在内存中的数据结构,B树的优势不明显,可能比其他平衡树(如红黑树)效率低。
- 更新开销:插入和删除操作可能导致级联的节点分裂或合并,增加了操作的复杂性。
应用场景
数据库系统是B树最主要的应用领域。几乎所有主流关系数据库都使用B树或其变种来实现索引。数据库引擎通过B树索引可以快速定位到数据所在的页面,极大提升查询性能。例如,MySQL的InnoDB存储引擎使用B+树(B树的变种)来构建其索引结构。
文件系统也广泛采用B树来组织文件和目录。如NTFS、HFS+等文件系统都使用B树或其变种来管理文件分配表和目录结构,有效地支持大型存储系统中的文件检索。
时间序列数据库或地理信息系统中,经常需要检索特定范围内的数据点,B树的有序特性使这类操作变得高效。
键值存储系统如Redis、LevelDB等也借鉴了B树的设计理念。虽然它们可能使用了不同的变种或混合结构,但基本思想源自B树的高效查找和范围操作特性。
B树的变种
B+树是B树的一个重要变种,它在数据库系统中更为常用:
- 所有数据都存储在叶节点
- 内部节点仅包含键,不包含数据
- 叶节点通过链表连接,支持更高效的顺序访问
- 适合范围查询和顺序扫描
B* 树对B树进行了进一步优化:
- 非根节点至少2/3满(而不是1/2)
- 在节点分裂前先尝试与兄弟节点重新分配
- 分裂时涉及两个节点变为三个节点
- 提高了空间利用率
B+树
B+树是一种平衡树数据结构,是B树的变种,被广泛应用于数据库索引和文件系统中。B+树保持数据有序,而且能够高效地进行查找、顺序访问、插入和删除操作。
B+树的主要组成部分包括:
- 节点:B+树中的基本单元,分为内部节点和叶子节点
- 内部节点:只存储键值和指向子节点的指针,不存储数据
- 叶子节点:存储键值和真实数据(或指向数据的指针)
- 阶数(order):表示一个节点最多可以有多少个子节点,通常用m表示
- 链表:所有叶子节点形成一个有序链表,方便范围查询
B+树核心特性
- 所有数据都存储在叶子节点上:内部节点只存储键值和指针,不存储实际数据
- 所有叶子节点通过指针连接成有序链表:便于范围查询和顺序遍历
- 平衡树结构:所有叶子节点到根节点的距离相同
- 高扇出性(High Fan-out):每个节点可以包含多个键值和指针,减少树的高度
- 自平衡:在插入和删除操作后自动调整以保持平衡
基本操作
查找操作
- 从根节点开始,根据键值比较确定应该查找哪个子节点
- 递归向下查找,直到到达叶子节点
- 在叶子节点中查找目标数据
插入操作
- 找到应插入的叶子节点
- 将数据插入到该叶子节点
- 如果叶子节点溢出(超过最大容量):
- 分裂节点为两部分
- 选择一个键值上升到父节点
- 如有必要,递归向上分裂
删除操作
- 找到包含目标数据的叶子节点
- 从叶子节点中删除数据
- 如果节点下溢(低于最小容量要求):
- 尝试从相邻节点借用数据
- 如果无法借用,则合并节点
- 如有必要,递归向上调整
优点
- 高效的范围查询:叶子节点构成链表,可以快速进行范围查询
- 更少的IO操作:高扇出性使树高度较低,减少磁盘访问次数
- 适合外部存储:节点可以映射到磁盘块,优化磁盘IO
- 动态平衡:插入删除后自动维持平衡状态
- 较大的分支因子:每个节点可以存储更多键值,减少树的高度
缺点
- 实现复杂:相比简单的树结构,实现较为复杂
- 修改开销大:插入和删除操作可能导致节点分裂或合并,级联影响多个节点
- 空间利用率:内部节点不存储数据,可能导致空间利用率不如其他结构
- 不适合频繁更新的场景:频繁的插入删除操作会导致频繁的树结构调整
应用场景
B+树在数据库系统和文件系统中得到了广泛应用。在数据库领域,几乎所有主流关系型数据库的索引结构都采用了B+树或其变种。MySQL的InnoDB存储引擎使用B+树作为其主要索引结构,通过将数据按主键顺序组织在叶子节点中,实现了高效的查询和范围扫描操作。
在文件系统中,B+树被用于管理文件的目录结构和索引,比如NTFS、ext4等现代文件系统。由于B+树能够高效地处理大量数据,同时保持较低的树高度,使文件系统能够快速定位和访问文件。
B+树还被广泛应用于地理信息系统(GIS)中的空间索引,快速查找特定地理区域内的对象。
Trie树
Trie树,也称为前缀树或字典树,是一种树形数据结构,专门用于高效存储和检索字符串集合。Trie这个名字来源于"retrieval"(检索)一词,反映了它的主要用途。
在Trie树中,每个节点代表一个字符,从根节点到某一节点的路径上经过的字符连接起来,就是该节点对应的字符串。Trie树的关键特点是,所有拥有相同前缀的字符串,在树中共享这个前缀的存储空间。
Trie树核心特性
- 前缀共享: 具有相同前缀的字符串在Trie树中共享存储空间,大大节省了内存
- 快速查找: 查找一个长度为k的字符串的时间复杂度为O(k),与Trie树中存储的字符串总数无关
- 词汇关联: 通过前缀可以轻松找到所有具有该前缀的单词
- 有序性: Trie树天然地保持了字典序
基本操作
Trie树支持以下基本操作:
- 插入(Insert): 将一个字符串添加到Trie树中
- 查找(Search): 检查一个完整的字符串是否存在于Trie树中
- 前缀查找(StartsWith): 检查Trie树中是否有以给定前缀开头的字符串
- 删除(Delete): 从Trie树中删除一个字符串(相对复杂)
基础实现
class Trie {
private TrieNode root;
// Trie树的节点结构
class TrieNode {
// 子节点,使用数组实现(假设只包含小写字母a-z)
private TrieNode[] children;
// 标记该节点是否为某个单词的结尾
private boolean isEndOfWord;
public TrieNode() {
children = new TrieNode[26]; // 26个英文字母
isEndOfWord = false;
}
}
/** 初始化Trie树 */
public Trie() {
root = new TrieNode();
}
/** 向Trie树中插入单词 */
public void insert(String word) {
TrieNode current = root;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
int index = ch - 'a'; // 将字符转换为索引
// 如果当前字符的节点不存在,创建一个新节点
if (current.children[index] == null) {
current.children[index] = new TrieNode();
}
// 移动到下一个节点
current = current.children[index];
}
// 标记单词结束
current.isEndOfWord = true;
}
/** 查找Trie树中是否存在完整单词 */
public boolean search(String word) {
TrieNode node = searchPrefix(word);
// 节点存在且是单词结尾
return node != null && node.isEndOfWord;
}
/** 查找Trie树中是否存在指定前缀 */
public boolean startsWith(String prefix) {
// 只需要节点存在即可
return searchPrefix(prefix) != null;
}
/** 查找前缀对应的节点 */
private TrieNode searchPrefix(String prefix) {
TrieNode current = root;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
int index = ch - 'a';
// 如果当前字符的节点不存在,返回null
if (current.children[index] == null) {
return null;
}
current = current.children[index];
}
return current;
}
/** 从Trie树中删除单词(较复杂的操作) */
public void delete(String word) {
delete(root, word, 0);
}
private boolean delete(TrieNode current, String word, int index) {
// 已经处理完所有字符
if (index == word.length()) {
// 如果不是单词结尾,单词不存在
if (!current.isEndOfWord) {
return false;
}
// 取消标记单词结尾
current.isEndOfWord = false;
// 如果节点没有子节点,可以删除
return hasNoChildren(current);
}
char ch = word.charAt(index);
int childIndex = ch - 'a';
TrieNode child = current.children[childIndex];
// 如果字符对应的节点不存在,单词不存在
if (child == null) {
return false;
}
// 递归删除子节点
boolean shouldDeleteChild = delete(child, word, index + 1);
// 如果子节点应该被删除
if (shouldDeleteChild) {
current.children[childIndex] = null;
// 如果当前节点不是单词结尾且没有其他子节点,则它也可以被删除
return !current.isEndOfWord && hasNoChildren(current);
}
return false;
}
private boolean hasNoChildren(TrieNode node) {
for (TrieNode child : node.children) {
if (child != null) {
return false;
}
}
return true;
}
}优点
- 高效的字符串检索:查找、插入和删除操作的时间复杂度与字符串长度成正比(O(k)),而与存储的字符串总数无关
- 节省空间:通过共享前缀,减少了重复存储
- 支持按字典序遍历:可以方便地按字典序输出所有字符串
- 前缀匹配高效:特别适合前缀查询和自动补全功能
缺点
- 内存消耗:对于不共享前缀的字符串集合,Trie树可能消耗大量内存
- 空间复杂度高:每个节点需要存储所有可能字符的引用(如上例中每个节点存储26个子节点引用)
- 不适合单次查询:如果只需要进行单次的精确字符串查询,哈希表可能是更好的选择
- 实现较为复杂:特别是删除操作,需要额外的逻辑来处理节点的清理
应用场景
- 自动补全和拼写检查:当用户在搜索框中输入时,Trie树可以快速找到所有以当前输入为前缀的单词,提供智能提示。输入法和文本编辑器通常利用这一特性实现单词补全功能。
- IP路由表:网络路由器使用类似Trie的结构来存储IP地址,实现高效的最长前缀匹配。
- 字典和词汇表:电子字典应用可以使用Trie树来存储词汇,支持快速查找和前缀搜索。
- 文本分析:在自然语言处理中,Trie树可以用于单词频率统计、关键词提取等任务。
- 电话号码簿:通讯录应用可以使用Trie树来存储联系人信息,支持按号码前缀搜索。
相关的LeetCode热门题目
- 208. 实现 Trie (前缀树) - 基础题,要求实现Trie树的基本操作。
- 211. 添加与搜索单词 - 数据结构设计 - 在基本Trie的基础上增加了通配符匹配功能。
- 212. 单词搜索 II - 使用Trie树优化在二维字符网格中搜索单词的过程。
- 648. 单词替换 - 使用Trie树查找词根并替换单词。
- 1032. 字符流 - 设计一个数据结构,支持对字符流的查询,判断最近添加的字符是否形成了给定单词集合中的某个单词的后缀。
树状数组
树状数组(Binary Indexed Tree),也称为Fenwick Tree,是一种支持高效的前缀和计算和单点更新的数据结构。它的核心思想是利用二进制的性质来维护数据间的层级关系,从而在O(log n)的时间内完成查询和更新操作。
树状数组的关键概念是"父子关系",这种关系是通过二进制表示中的最低位1来确定的。对于任意一个节点i,它的父节点是i + (i & -i),它的子节点是i - (i & -i)。
- i & -i 表达式计算的是i的二进制表示中的最低位1对应的值
- 例如:6的二进制是110,6&(-6) = 6&(010) = 2
树状数组通常使用一个一维数组表示,采用1-indexed(即从索引1开始存储有效数据)的方式:
- BIT[i]存储了原始数组中某个区间的和
- 每个BIT[i]负责管理的区间长度由i & -i决定
- 例如,BIT[6]管理的区间长度是2,包含原始数组中的A[5]和A[6]
基本操作
- 更新操作(update):更新原始数组中索引i的值时,需要更新树状数组中所有包含该索引的节点。
- 从索引i开始
- 不断地加上i & -i,直到超出数组范围
- 在每一步都更新对应的树状数组值
public void update(int i, int delta) {
i = i + 1; // 转为1-based索引
while (i <= n) {
bit[i] += delta;
i += i & -i; // 移动到父节点
}
}- 查询前缀和(query):查询从1到i的所有元素的和。
- 从索引i开始
- 不断地减去i & -i,直到i变为0
- 在每一步都累加对应的树状数组值
public int query(int i) {
i = i + 1; // 转为1-based索引
int sum = 0;
while (i > 0) {
sum += bit[i];
i -= i & -i; // 移动到前一个节点
}
return sum;
}时间复杂度:
- 初始化:O(n log n)
- 单点更新:O(log n)
- 前缀和查询:O(log n)
- 区间查询:O(log n)
应用场景
树状数组在以下场景中特别有用:
- 频繁的区间查询和单点更新:如果需要经常计算前缀和并且数组中的值会频繁变化,树状数组是一个很好的选择。
- 计数应用:如逆序对计数、区间统计等。
- 2D/多维前缀和:树状数组可以很容易地扩展到多维空间,处理二维甚至多维的前缀和查询。
- 动态排名统计:通过树状数组可以维护一个动态的排名统计。
树状数组的优势
- 实现简单:相比于线段树,树状数组的代码更加简洁。
- 常数因子小:在实际应用中,树状数组通常比线段树更快,因为它的常数因子更小。
- 空间效率高:树状数组只需要与原始数组相同大小的空间。
区间更新
通过差分数组技术,树状数组可以支持区间更新,但查询变为单点查询,这样就能在O(log n)时间内完成区间更新操作。
// 创建树状数组(假设已实现BinaryIndexedTree类)
BinaryIndexedTree bit = new BinaryIndexedTree(new int[]{0, 2, 1, 4, 3, 6, 5});
// 查询前缀和
System.out.println("query(2): " + bit.query(2)); // 索引0到2的和: 2+1+4=7
// 更新元素值
bit.update(1, 2); // 将索引1的元素增加2
System.out.println("query(2): " + bit.query(2)); // 现在索引0到2的和: 2+(1+2)+4=9
// 区间查询
System.out.println("rangeQuery(1, 3): " + bit.rangeQuery(1, 3)); // 索引1到3的和: (1+2)+4+3=10线段树
线段树(Segment Tree)是一种高效的数据结构,专门用于解决区间查询和区间修改问题。与树状数组相比,线段树功能更加强大,可以支持更多种类的区间操作。
线段树的核心思想是通过分治法将一个区间划分为多个子区间,并用树的形式组织这些区间的信息。在这棵树中,每个节点代表一个区间,根节点代表整个数组区间,叶子节点代表单个元素。
核心概念解释:
- 区间查询:查询数组中某个区间的聚合信息(如区间和、最大值、最小值等)
- 区间修改:修改数组中某个区间内所有元素的值
- 懒惰标记(Lazy Propagation):延迟更新策略,用于提高区间修改的效率
- 树节点:每个节点存储其对应区间的信息,如区间和、最大值等
线段树核心特性:
- 灵活的区间操作:支持各种区间查询(和、最大值、最小值、异或和等)和区间修改
- 高效的时间复杂度:查询和修改的时间复杂度均为O(log n)
- 强大的扩展性:可以根据需求自定义区间操作的类型
- 适应动态变化:能够处理数组内容频繁变化的情况
线段树的工作原理
线段树的结构:
线段树是一棵完全二叉树,其中:
- 根节点代表整个数组区间[0, n-1]
- 每个非叶节点的左子节点代表区间的左半部分,右子节点代表右半部分
- 叶子节点代表单个元素(长度为1的区间)
懒惰标记(Lazy Propagation):
懒惰标记是一种优化技术,用于延迟区间修改的传播。当一个节点的所有子节点都需要被修改时,我们不立即修改这些子节点,而是在节点上标记修改信息,只有在需要访问子节点时才将修改下推,提高区间修改的效率。
基本操作
- 构建(build):根据初始数组构建线段树
- 区间查询(query):查询某个区间的聚合信息
- 单点修改(update):修改单个元素的值
- 区间修改(updateRange):修改一段区间内所有元素的值(通常使用懒惰标记实现)
基础实现
下面是线段树的基础实现(以区间和为例):
public class SegmentTree {
private int[] tree; // 存储线段树节点
private int[] lazy; // 懒惰标记
private int[] nums; // 原始数组的副本
private int n; // 原始数组长度
public SegmentTree(int[] array) {
n = array.length;
// 线段树数组大小一般为原数组大小的4倍
tree = new int[4 * n];
lazy = new int[4 * n];
nums = array.clone();
build(0, 0, n - 1);
}
// 构建线段树
private void build(int node, int start, int end) {
if (start == end) {
// 叶子节点,存储单个元素
tree[node] = nums[start];
return;
}
int mid = (start + end) / 2;
int leftNode = 2 * node + 1;
int rightNode = 2 * node + 2;
// 递归构建左右子树
build(leftNode, start, mid);
build(rightNode, mid + 1, end);
// 合并子节点的信息
tree[node] = tree[leftNode] + tree[rightNode];
}
// 单点修改
public void update(int index, int val) {
// 计算与原值的差值
int diff = val - nums[index];
nums[index] = val;
updateSingle(0, 0, n - 1, index, diff);
}
private void updateSingle(int node, int start, int end, int index, int diff) {
// 检查索引是否在当前节点范围内
if (index < start || index > end) {
return;
}
// 更新当前节点的值
tree[node] += diff;
if (start != end) {
int mid = (start + end) / 2;
int leftNode = 2 * node + 1;
int rightNode = 2 * node + 2;
// 递归更新子节点
updateSingle(leftNode, start, mid, index, diff);
updateSingle(rightNode, mid + 1, end, index, diff);
}
}
// 区间查询
public int query(int left, int right) {
return queryRange(0, 0, n - 1, left, right);
}
private int queryRange(int node, int start, int end, int left, int right) {
// 如果当前节点的区间完全在查询区间外
if (right < start || left > end) {
return 0;
}
// 如果当前节点的区间完全在查询区间内
if (left <= start && end <= right) {
return tree[node];
}
// 处理懒惰标记
if (lazy[node] != 0) {
tree[node] += (end - start + 1) * lazy[node];
if (start != end) {
lazy[2 * node + 1] += lazy[node];
lazy[2 * node + 2] += lazy[node];
}
lazy[node] = 0;
}
// 查询范围部分覆盖当前节点的区间,需要分别查询左右子节点
int mid = (start + end) / 2;
int leftSum = queryRange(2 * node + 1, start, mid, left, right);
int rightSum = queryRange(2 * node + 2, mid + 1, end, left, right);
return leftSum + rightSum;
}
// 区间修改
public void updateRange(int left, int right, int val) {
updateRangeTree(0, 0, n - 1, left, right, val);
}
private void updateRangeTree(int node, int start, int end, int left, int right, int val) {
// 处理当前节点的懒惰标记
if (lazy[node] != 0) {
tree[node] += (end - start + 1) * lazy[node];
if (start != end) {
lazy[2 * node + 1] += lazy[node];
lazy[2 * node + 2] += lazy[node];
}
lazy[node] = 0;
}
// 如果当前节点的区间完全在修改区间外
if (right < start || left > end) {
return;
}
// 如果当前节点的区间完全在修改区间内
if (left <= start && end <= right) {
tree[node] += (end - start + 1) * val;
if (start != end) {
lazy[2 * node + 1] += val;
lazy[2 * node + 2] += val;
}
return;
}
// 修改范围部分覆盖当前节点的区间,需要分别修改左右子节点
int mid = (start + end) / 2;
updateRangeTree(2 * node + 1, start, mid, left, right, val);
updateRangeTree(2 * node + 2, mid + 1, end, left, right, val);
// 更新当前节点的值
tree[node] = tree[2 * node + 1] + tree[2 * node + 2];
}
}优点
- 功能强大:支持多种区间操作,包括区间求和、最大值、最小值等
- 操作灵活:同时支持区间查询和区间修改
- 时间效率高:所有操作的时间复杂度均为O(log n)
- 可扩展性好:可以根据具体问题自定义节点存储的信息和操作方式
缺点
- 内存消耗较大:需要额外的内存来存储线段树结构,通常为原数组大小的4倍
- 代码实现复杂:相比其他数据结构(如树状数组),实现和调试更加复杂
- 常数因子较大:虽然时间复杂度是O(log n),但实际运行时间可能比树状数组等结构略长
应用场景
线段树在许多实际问题中有广泛应用,特别是在需要同时支持区间查询和区间修改的情况下:
- 范围检索系统:在数据库和信息检索系统中,线段树可用于快速查询满足特定条件的数据范围。例如,在时间序列数据库中,快速查找某一时间段内的最大/最小值或平均值。
- 图像处理:在处理大型图像数据时,线段树可用于快速计算图像某一区域的统计信息或实现区域性的图像编辑操作。
- 计算几何:在处理二维空间中的点、线或矩形等几何对象时,线段树可以高效地解决区间查询问题,如找出与给定区域相交的所有对象。
- 在线算法竞赛:线段树是解决动态范围查询问题的标准工具,如区间最大值、区间和等问题。
- 游戏开发:在大型多人在线游戏中,线段树可用于地图数据的管理和快速查询,如找出某区域内的所有游戏对象。
动态线段树
当区间范围非常大,但实际有值的点比较稀疏时,可以使用动态线段树(通常使用指针实现)来节省空间:
public class DynamicSegmentTree {
private class Node {
int val; // 节点值
int lazy; // 懒惰标记
Node left; // 左子节点
Node right; // 右子节点
int start; // 区间起点
int end; // 区间终点
Node(int start, int end) {
this.start = start;
this.end = end;
this.val = 0;
this.lazy = 0;
}
}
private Node root;
public DynamicSegmentTree(int start, int end) {
root = new Node(start, end);
}
// 区间更新
public void update(int left, int right, int val) {
update(root, left, right, val);
}
private void update(Node node, int left, int right, int val) {
// 如果区间完全在更新范围外
if (node.end < left || node.start > right) {
return;
}
// 如果区间完全在更新范围内
if (node.start >= left && node.end <= right) {
node.val += (node.end - node.start + 1) * val;
if (node.start != node.end) {
node.lazy += val;
}
return;
}
// 下推懒惰标记
pushDown(node);
// 更新左右子节点
if (node.left != null) {
update(node.left, left, right, val);
}
if (node.right != null) {
update(node.right, left, right, val);
}
// 更新当前节点的值
node.val = (node.left != null ? node.left.val : 0) +
(node.right != null ? node.right.val : 0);
}
// 区间查询
public int query(int left, int right) {
return query(root, left, right);
}
private int query(Node node, int left, int right) {
// 如果区间完全在查询范围外
if (node.end < left || node.start > right) {
return 0;
}
// 如果区间完全在查询范围内
if (node.start >= left && node.end <= right) {
return node.val;
}
// 下推懒惰标记
pushDown(node);
int sum = 0;
if (node.left != null) {
sum += query(node.left, left, right);
}
if (node.right != null) {
sum += query(node.right, left, right);
}
return sum;
}
// 下推懒惰标记
private void pushDown(Node node) {
if (node.lazy == 0) {
return;
}
int mid = (node.start + node.end) / 2;
// 创建左子节点(如果不存在)
if (node.left == null) {
node.left = new Node(node.start, mid);
}
// 创建右子节点(如果不存在)
if (node.right == null) {
node.right = new Node(mid + 1, node.end);
}
// 更新子节点的值和懒惰标记
node.left.val += (node.left.end - node.left.start + 1) * node.lazy;
node.right.val += (node.right.end - node.right.start + 1) * node.lazy;
if (node.left.start != node.left.end) {
node.left.lazy += node.lazy;
}
if (node.right.start != node.right.end) {
node.right.lazy += node.lazy;
}
// 清除当前节点的懒惰标记
node.lazy = 0;
}
}可持久化线段树(Persistent Segment Tree)
可持久化线段树是线段树的一种变体,它可以保存历史版本,允许查询任意历史状态:
public class PersistentSegmentTree {
private class Node {
int val; // 节点值
Node left; // 左子节点
Node right; // 右子节点
Node(int val) {
this.val = val;
this.left = null;
this.right = null;
}
Node(Node other) {
this.val = other.val;
this.left = other.left;
this.right = other.right;
}
}
private Node[] roots; // 存储历史版本的根节点
private int n; // 数组大小
private int versionCount; // 版本数量
public PersistentSegmentTree(int[] array, int maxVersions) {
n = array.length;
roots = new Node[maxVersions];
versionCount = 0;
// 构建初始版本
roots[versionCount++] = build(0, n - 1, array);
}
// 构建线段树
private Node build(int start, int end, int[] array) {
if (start == end) {
return new Node(array[start]);
}
int mid = (start + end) / 2;
Node node = new Node(0);
node.left = build(start, mid, array);
node.right = build(mid + 1, end, array);
node.val = node.left.val + node.right.val;
return node;
}
// 创建新版本并更新单个元素
public void update(int index, int val) {
roots[versionCount] = update(roots[versionCount - 1], 0, n - 1, index, val);
versionCount++;
}
private Node update(Node node, int start, int end, int index, int val) {
if (index < start || index > end) {
return node;
}
// 创建新节点(路径复制)
Node newNode = new Node(node);
if (start == end) {
newNode.val = val;
return newNode;
}
int mid = (start + end) / 2;
if (index <= mid) {
newNode.left = update(node.left, start, mid, index, val);
} else {
newNode.right = update(node.right, mid + 1, end, index, val);
}
newNode.val = newNode.left.val + newNode.right.val;
return newNode;
}
// 查询特定版本的区间和
public int query(int version, int left, int right) {
if (version >= versionCount) {
throw new IllegalArgumentException("版本不存在");
}
return query(roots[version], 0, n - 1, left, right);
}
private int query(Node node, int start, int end, int left, int right) {
if (right < start || left > end) {
return 0;
}
if (left <= start && end <= right) {
return node.val;
}
int mid = (start + end) / 2;
return query(node.left, start, mid, left, right) +
query(node.right, mid + 1, end, left, right);
}
}相关LeetCode热门题目
- 307. 区域和检索 - 数组可修改:设计一个支持区间和查询和单点修改的数据结构,可以使用线段树高效解决。
- 699. 掉落的方块:使用线段树来跟踪区间的最大高度,解决方块堆叠问题。
- 715. Range模块:实现一个数据结构来管理区间的添加、删除和查询,线段树是理想的解决方案。
- 218. 天际线问题:使用线段树来处理建筑物的高度信息,求解城市天际线。
- 1157. 子数组中占绝大多数的元素:使用线段树结合分治思想解决区间众数查询问题。
