题⽬描述
如何得到⼀个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。我们使⽤ Insert() ⽅法读取数据流,使⽤ GetMedian() ⽅法获取当前读取数据的中位数。
思路及解答
排序列表法
这个方案使用 ArrayList 保存数据流中的所有数字。每次调用 Insert(num) 时,先把 num 加入列表末尾,然后通过 Collections.sort(data) 对整个列表重新排序,保证 data 始终是有序的。
查询中位数时,只需要根据列表长度的奇偶性判断即可。如果元素个数是奇数,中位数就是中间位置 data.get(size / 2);如果元素个数是偶数,中位数就是中间两个元素 data.get(mid - 1) 和 data.get(mid) 的平均值。
这种方法实现简单,查询中位数的时间复杂度是 O(1),但每次插入都要重新排序,插入成本较高,适合数据量不大或更关注代码简单性的场景。


import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class MedianFinder1 {
private List<Integer> data;
public MedianFinder1() {
data = new ArrayList<>();
}
// 插入数字到数据流
public void Insert(Integer num) {
data.add(num);
// 每次插入后排序,保持列表有序
Collections.sort(data);
}
// 获取当前数据流的中位数
public Double GetMedian() {
int size = data.size();
if (size == 0) return 0.0;
if (size % 2 == 1) {
// 奇数个元素,返回中间值
return (double) data.get(size / 2);
} else {
// 偶数个元素,返回中间两个数的平均值
int mid = size / 2;
return (data.get(mid - 1) + data.get(mid)) / 2.0;
}
}
}- 插入操作:每次插入需要排序,时间复杂度O(n log n)
- 获取中位数:直接通过索引访问,时间复杂度O(1)
- 空间复杂度:O(n),需要存储所有数据
插入排序法
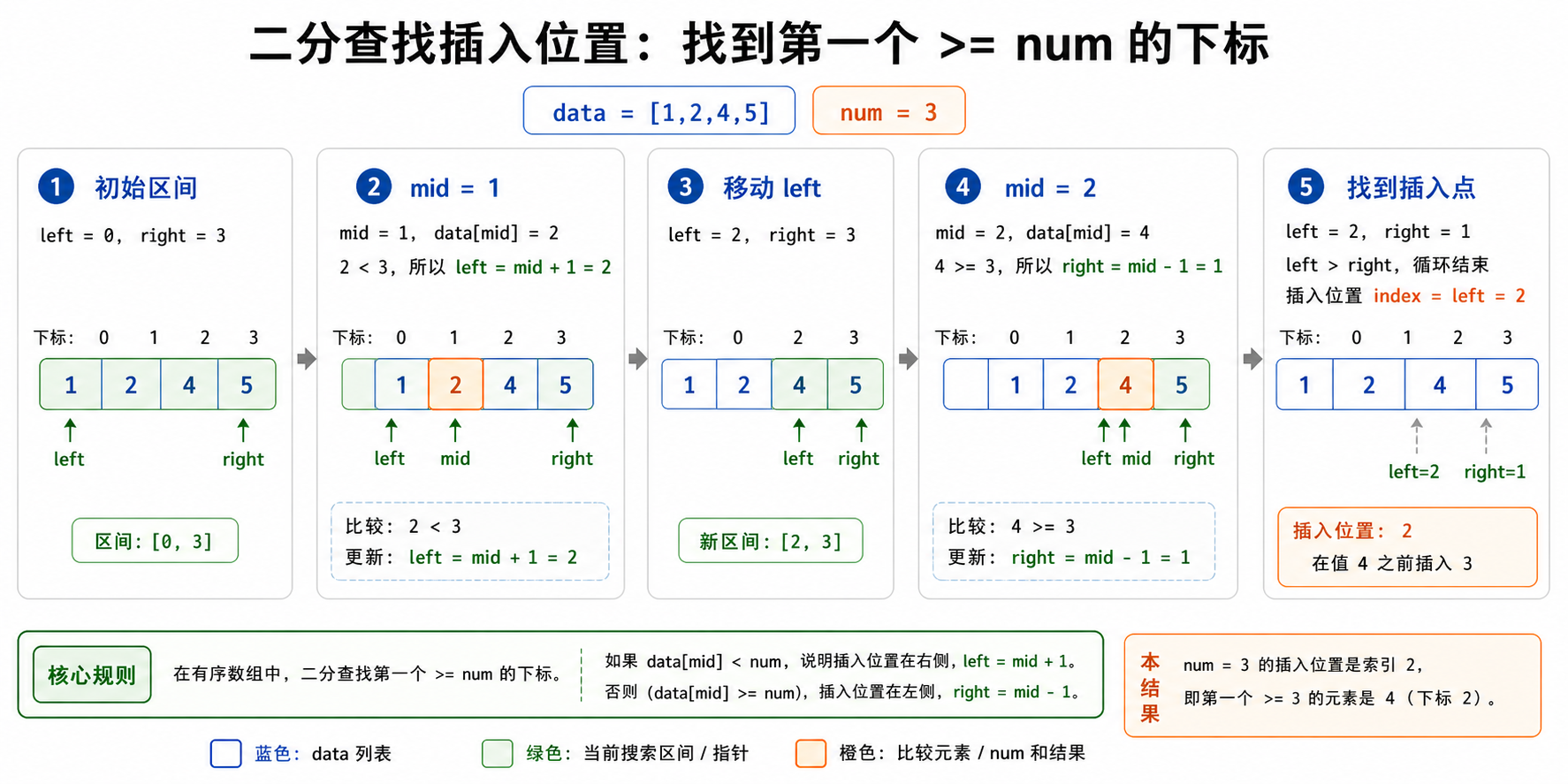
这个方法在 ArrayList + 排序方案的基础上做了优化:不再每次插入后对整个列表重新排序,而是在插入之前通过二分查找找到正确位置。
由于 data 始终保持有序,所以插入 num 时,可以用 left、right、mid 在有序列表中查找第一个大于等于 num 的位置。循环结束后,left 就是 num 应该插入的位置。
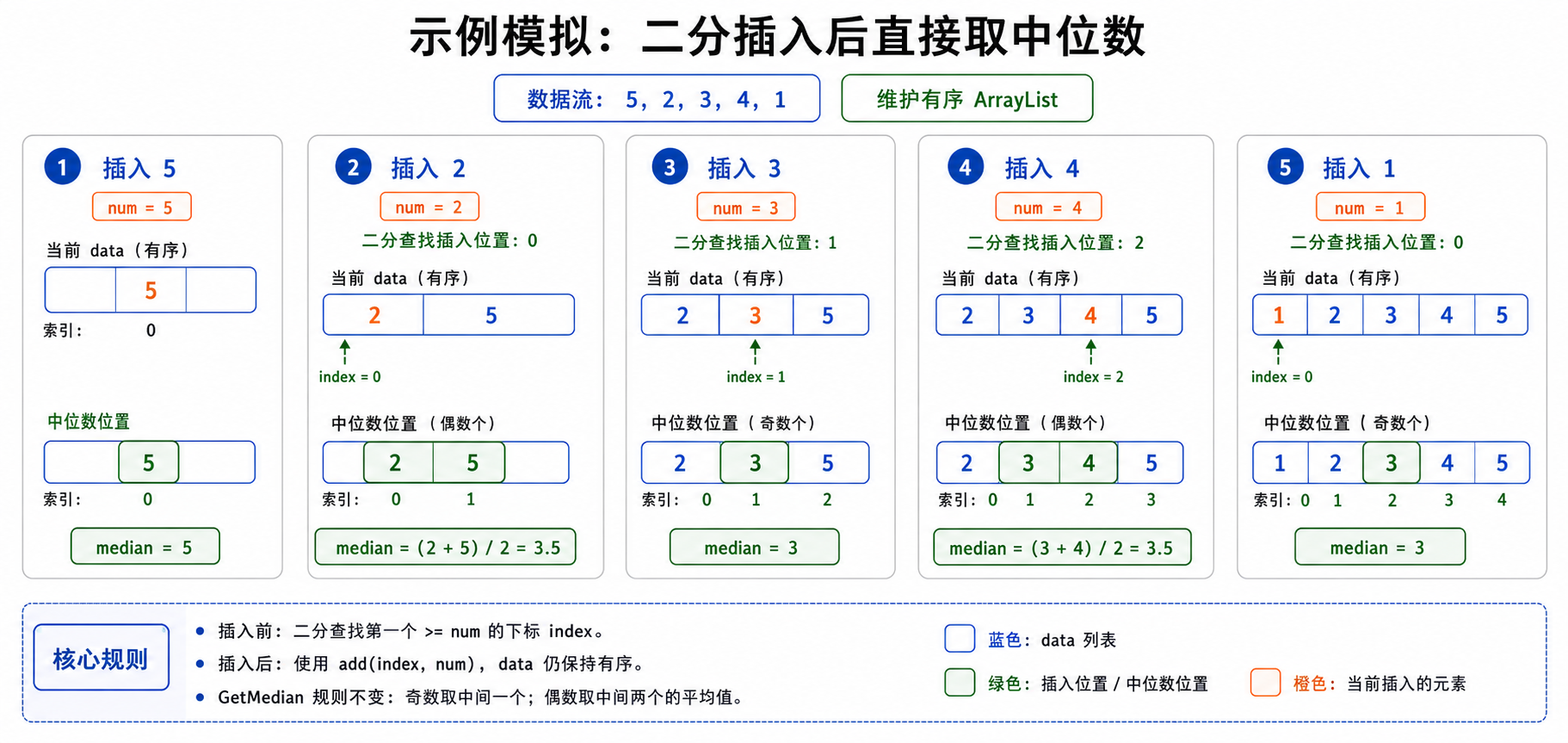
找到位置后,调用 data.add(left, num) 将元素插入到对应下标。这样插入完成后,data 仍然保持有序,GetMedian 的逻辑和方法一完全相同:奇数个元素取中间一个,偶数个元素取中间两个的平均值。
需要注意的是,二分查找把“找位置”的时间降到了 O(log n),但 ArrayList 在中间插入元素时仍然需要移动后面的元素,所以单次插入的整体时间复杂度仍是 O(n)。
import java.util.ArrayList;
import java.util.List;
public class MedianFinder2 {
private List<Integer> data;
public MedianFinder2() {
data = new ArrayList<>();
}
public void Insert(Integer num) {
// 使用二分查找找到合适的插入位置
int left = 0, right = data.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (data.get(mid) < num) {
left = mid + 1;
} else {
right = mid - 1;
}
}
// 在找到的位置插入元素
data.add(left, num);
}
public Double GetMedian() {
int size = data.size();
if (size == 0) return 0.0;
if (size % 2 == 1) {
return (double) data.get(size / 2);
} else {
int mid = size / 2;
return (data.get(mid - 1) + data.get(mid)) / 2.0;
}
}
}- 插入操作:二分查找O(log n) + 插入操作O(n) = O(n)
- 获取中位数:O(1),通过索引直接访问
- 优化效果:比方法一有明显提升,特别适合部分有序的数据
双堆法
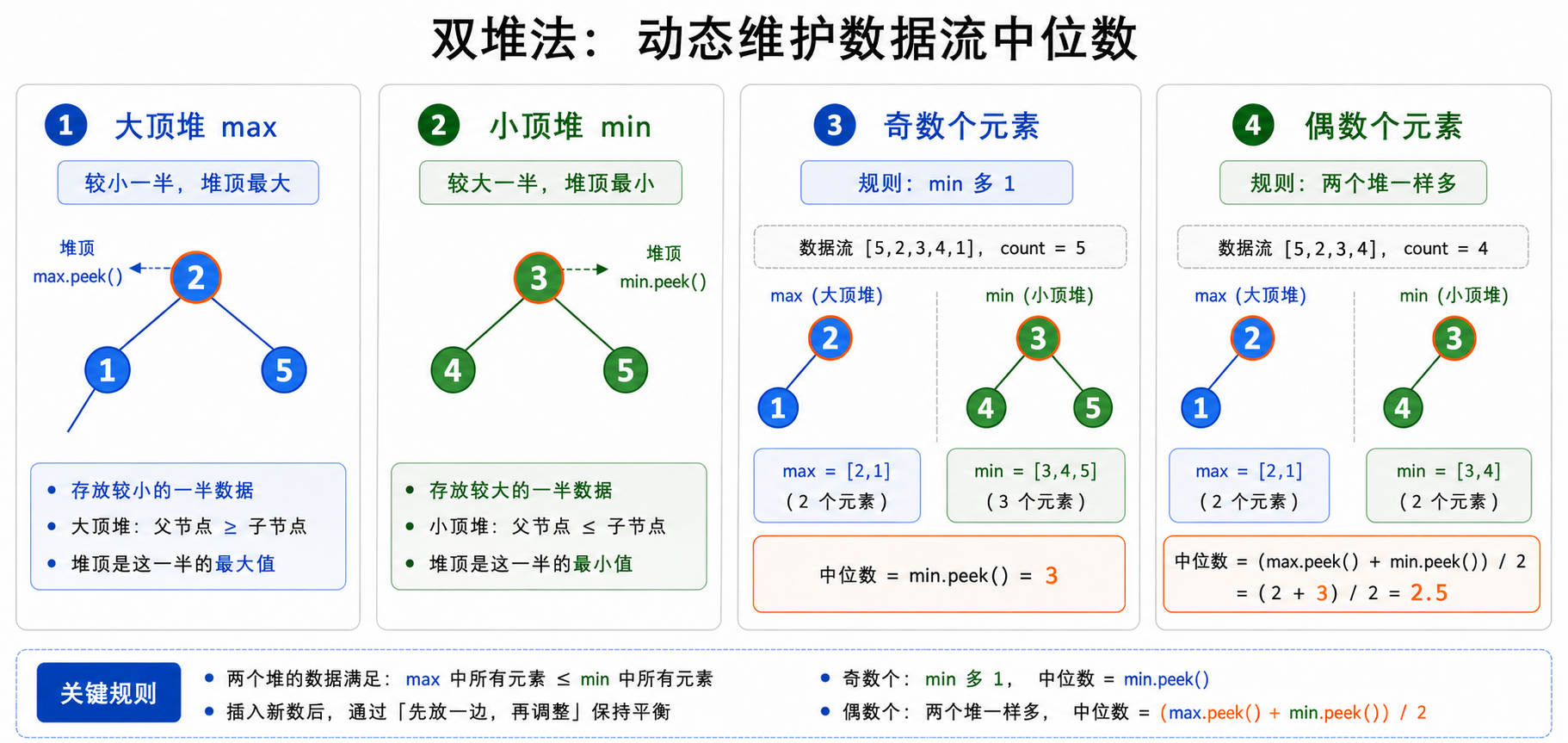
双堆法使用两个堆动态维护数据流的中位数。
大顶堆 max 保存较小的一半数据,堆顶是较小一半中的最大值;小顶堆 min 保存较大的一半数据,堆顶是较大一半中的最小值。这样,中位数一定和两个堆的堆顶有关。
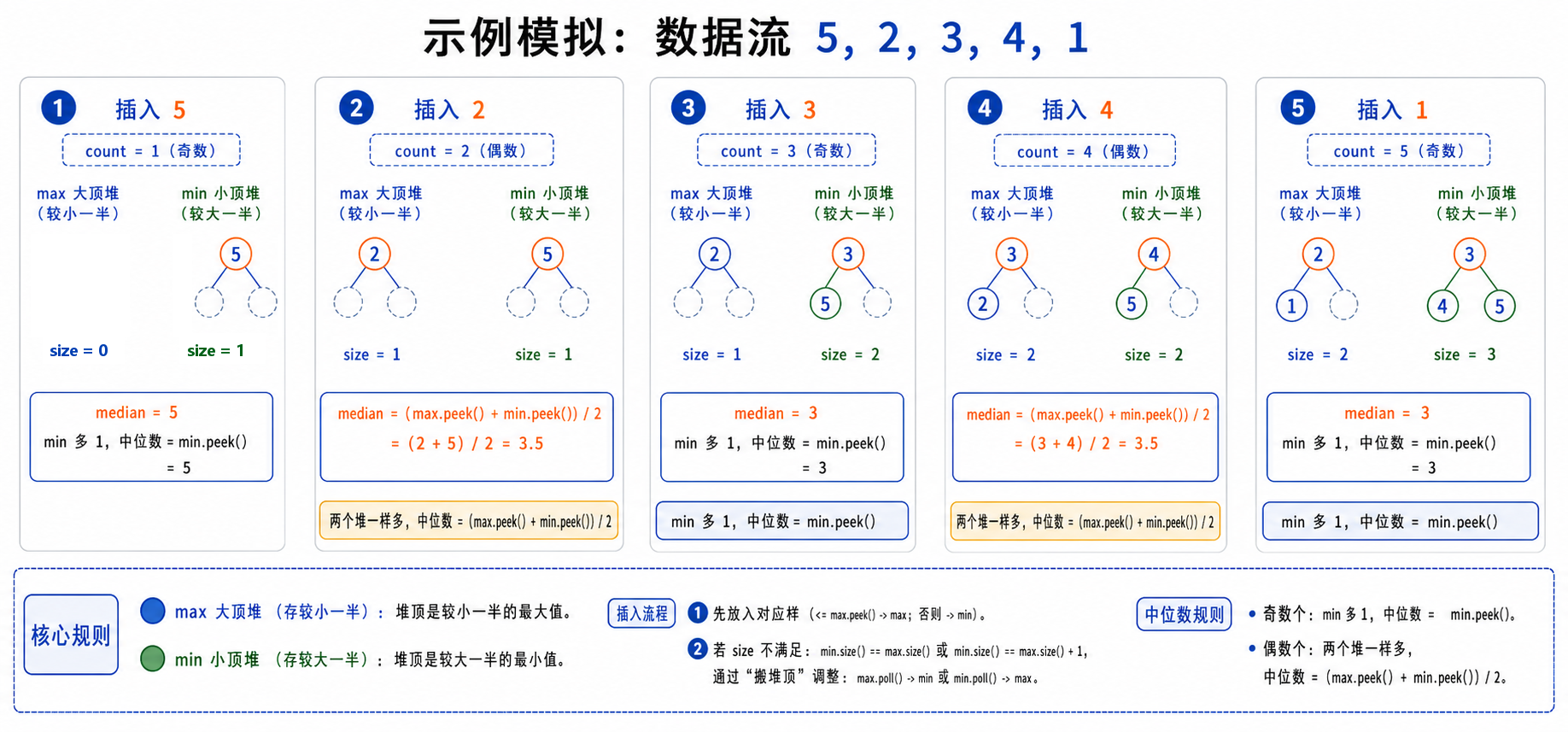
⽤⼀个数字来不断统计数据流中的个数,并且创建⼀个最⼤堆,⼀个最⼩堆,为了方便查询,代码让 min 的元素个数始终等于 max,或者比 max 多 1 个。
- 如果插⼊的数字的个数是奇数的时候,让最⼩堆⾥⾯的元素个数⽐最⼤堆的个数多 1 ,这样⼀来中位数就是⼩顶堆的堆顶
- 如果插⼊的数字的个数是偶数的时候,两个堆的元素保持⼀样多,中位数就是两个堆的堆顶的元素相加除以2 。
public class Solution {
private int count = 0;
private PriorityQueue<Integer> min = new PriorityQueue<Integer>();
private PriorityQueue<Integer> max = new PriorityQueue<Integer>(new Comparator<Integer>() {
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
public void Insert(Integer num) {
count++;
if (count % 2 == 1) {
// 奇数的时候,需要最⼩堆的元素⽐最⼤堆的元素多⼀个。
// 先放到最⼤堆⾥⾯,然后弹出最⼤的
max.offer(num);
// 把最⼤的放进最⼩堆
min.offer(max.poll());
} else {
// 放进最⼩堆
min.offer(num);
// 把最⼩的放进最⼤堆
max.offer(min.poll());
}
}
public Double GetMedian() {
if (count % 2 == 0) {
return (min.peek() + max.peek()) / 2.0;
} else {
return (double) min.peek();
}
}
}- 插入操作:堆的插入操作O(log n),平衡操作O(log n),总体O(log n)
- 获取中位数:直接访问堆顶元素,O(1)时间复杂度
- 空间复杂度:O(n),需要存储所有数据
为什么这种方法有效?
- 大顶堆(maxHeap):存储数据流中较小的一半数字,堆顶是这一半中的最大值
- 小顶堆(minHeap):存储数据流中较大的一半数字,堆顶是这一半中的最小值
- 平衡维护:确保两个堆的大小相差不超过1,这样中位数就只与两个堆顶有关