大部分互联网公司都需要处理计数器场景,例如风控系统的请求频控、内容平台的播放量统计、电商系统的库存扣减等。
传统方案一般会直接使用RedisUtil.incr(key),这是最简单的方式,但这种方式在生产环境中会暴露严重问题:
// 隐患示例
public long addOne(String key) {
Long result = RedisUtil.incr(key);
// 若未设置TTL,key将永久驻留内存
return result;
}大部分互联网公司都需要处理计数器场景,例如风控系统的请求频控、内容平台的播放量统计、电商系统的库存扣减等。
传统方案一般会直接使用RedisUtil.incr(key),这是最简单的方式,但这种方式在生产环境中会暴露严重问题:
// 隐患示例
public long addOne(String key) {
Long result = RedisUtil.incr(key);
// 若未设置TTL,key将永久驻留内存
return result;
}Redis是一个高效的内存数据库,它支持包括String、List、Set、SortedSet和Hash等数据类型的存储,在Redis中通常根据数据的key查询其value值,Redis没有模糊条件查询,在面对一些需要分页、排序以及条件查询的场景时(如评论,时间线,检索等),只凭借Redis所提供的功能就不太好不处理了。
本文不对Redis的特性做过多赘述。由于之前基于业务问题需要实现基于Redis的条件查询和分页功能,在百度上查询了不少文章,基本不是只有分页功能就是只有条件查询功能的实现,缺少两者组合的解决方案。因此,本文将基于Redis提供条件查询+分页的技术解决方案。
今天来讲讲 Redis 的请求监听,通俗点说,就是Redis是如何监听客户端发出的set、get等命令的。
众所周知,Redis 是单进程单线程架构,虽然是单进程单线程,但是Redis的性能却毫不逊色,能轻松应对一般的高并发场景,那么Redis究竟是施了什么魔法呢?
其实 Redis 的原理和 Nginx 差不多,都利用了 IO 多路复用来提高处理能力,所谓多路复用,就是一个线程可以同时处理多个IO操作,当 某个 IO 操作 Ready 时,操作系统会主动通知进程。使用 IO 多路复用,我们可以使用 epoll、kqueue、select,API 都差不多。
net stop mysql
net start mysql一般来说,事务越大,拿到的锁就越多,因此死锁的可能性就越大。
MySQL 以页作为数据的基本存储单位,每个页内包含两个主要的链表:正常记录链表和垃圾链表。每条记录都有一个记录头,记录头中包括一个关键属性——deleted_flag。
一般来说,现在的redis连接都会有池化技术, Redis连接池技术有以下好处:
资源复用:连接池允许多个客户端共享一定数量的数据库连接。当一个客户端完成操作并释放连接时,这个连接可以被另一个客户端重用,而不是关闭后重新建立,这大大减少了创建和销毁连接所需的时间和资源。
减少等待时间:预创建的连接可以立即提供给需要它们的客户端。这意味着应用程序不需要等待建立连接就可以执行操作,从而提高了响应速度。
提高性能:连接池可以减少因频繁打开和关闭连接造成的开销,因为建立数据库连接通常是一个高成本的操作,包括网络延迟、认证等过程。
连接数控制:连接池可以限制系统中活跃的总连接数。这防止了系统打开过多的连接,从而避免了对数据库服务器资源的过度消耗和可能的拒绝服务。
自动管理:连接池通常提供自动化的连接管理功能,如检测空闲连接、移除无效连接等,而不需要开发者手动干预。
减轻数据库压力:通过重用连接,连接池使得数据库服务器不必处理大量短生命周期的连接,这有助于维持数据库的稳定性和性能。
配置灵活性:可以根据应用程序的负载特征和数据库服务器的能力对连接池进行配置,如调整池的大小、连接的生命周期等。
故障恢复:当某个连接发生故障时,连接池可以提供一个新的连接替代它,从而增强了应用程序的鲁棒性。
更好的并发处理:在高并发环境下,连接池可以更有效地管理不同线程或进程的连接需求,减少了锁的竞争和上下文切换的成本。
简化编程模型:开发者可以从连接池中获取连接,执行操作,然后返回连接,而无需关心连接的创建和关闭,简化了编程模型。
计算Redis容量,并不只是仅仅计算key占多少字节,value占多少字节,因为Redis为了维护自身的数据结构,也会占用部分内存,本文章简单介绍每种数据类型(String、Hash、Set、ZSet、List)占用内存量,供做Redis容量评估时使用。
在看这里之前,可以先看一下底层 - 数据结构 这篇文章
数据访问代理服务端内部使用连接池访问物理数据库。合理的连接参数配置不仅有助于提升数据访问性能,而且能够保障数据库的稳定性。
connectTimeout:创建数据库连接超时时间。socketTimeout:SQL 请求超时时间,操作系统 socket 的超时时间,即一次 SQL 请求如果在该时间内没有返回任何数据,操作系统会抛出 Read timeout 的异常。txTimeout:数据访问代理事务超时时间,默认为 10 分钟。该参数是为了保护 ODP 的连接池不会被长事务占满,而影响业务的正常访问。目前该值不能修改,后续提供业务自定义配置。idleTimeoutMinutes:连接空闲时间,超过该时间则会被剔除出连接池,默认为 12 分钟。connectionProperties 通过 KV 键值对进行配置。min:单个分库的最小连接数。如果 min> 0,启动时会自动创建 min 个连接。max:单个分库的最大连接数。Redis中的数据类型指的是 value存储的数据类型,key都是以String类型存储的,value根据场景需要,可以以String、List等类型进行存储。
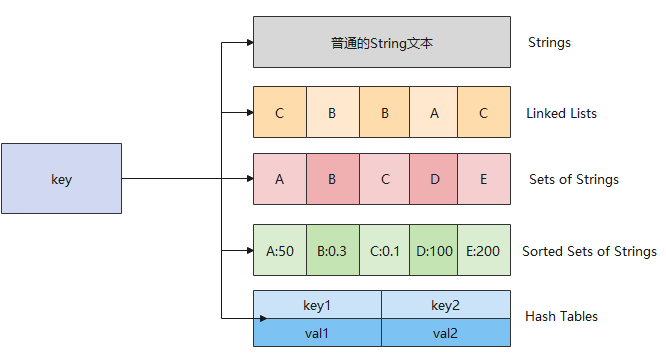
各数据类型介绍:
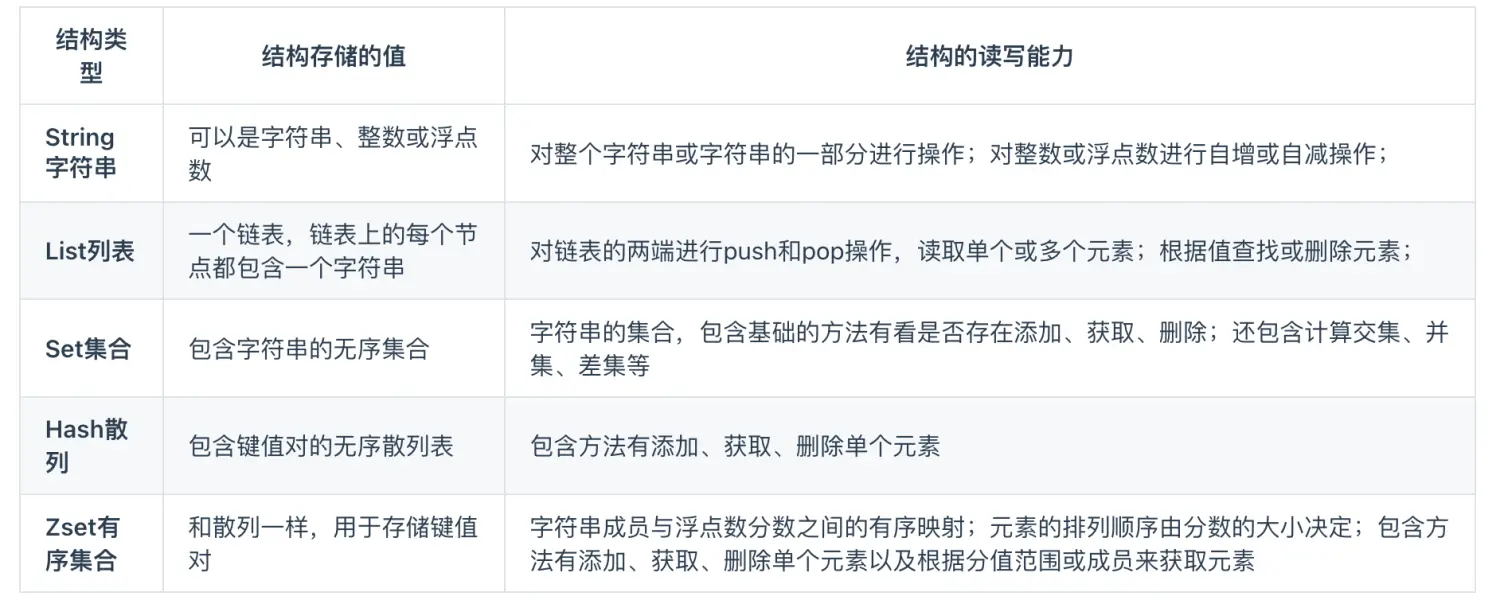
Redis 的键值对中的 key 就是字符串对象,而 value 就是指Redis的数据类型,可以是String,也可以是List、Hash、Set、 Zset 的数据类型。
其实是Redis 底层使用了一个全局哈希表保存所有键值对,哈希表的最大好处就是 O(1) 的时间复杂度快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。
